
Cloudflare BYOIP Outage: Your Resilience Playbook
On February 20, 2026, a configuration change at Cloudflare unintentionally withdrew around 1,100 Bring Your Own IP (BYOIP) prefixes from the internet. For affected customers, traffic couldn’t find a route, users hit timeouts, and a subset of Cloudflare’s own 1.1.1.1 destination (one.one.one.one) returned HTTP 403 “Edge IP Restricted.” The total incident lasted 6 hours and 7 minutes from first impact to full restoration of configurations. If your business leans on any CDN or edge provider, treat this Cloudflare BYOIP outage as the clearest signal yet to shore up routing, failover, and change management.
What actually failed on February 20, 2026?
Cloudflare runs an Addressing API that orchestrates how customer-owned prefixes are advertised to the internet. A change intended to automate safe removal of prefixes went wrong, and a regularly scheduled process began withdrawing active BYOIP prefixes instead. Once withdrawn, BGP did what BGP does: it hunted for alternative paths that didn’t exist, creating long, frustrating timeouts until advertisements were restored.
Key facts worth internalizing:
- Impact window: First effects began late afternoon UTC and recovery work concluded that evening. Cloudflare measured 6 hours 7 minutes to fully restore correct configurations across the fleet.
- Scope: Approximately 1,100 prefixes were withdrawn at peak. Cloudflare has indicated there are thousands of BYOIP prefixes in play; a subset were impacted before rollback halted further damage.
- Blast radius behavior: Because the rollout was iterative, not every BYOIP customer was hit—and some who were could self‑remediate by re‑advertising their prefixes in the dashboard.
Here’s the thing: this wasn’t a DDoS or exploitation. It was a control‑plane automation slip that cascaded quickly across routing. That’s precisely the class of incident most organizations underestimate.
Why the Cloudflare BYOIP outage hit so hard
Routing failures don’t degrade gracefully. When advertisements vanish, users aren’t simply slower—they’re gone. BGP “path hunting” drags out failed attempts, amplifying user pain and masking the root cause for app teams staring at 5xx spikes. Meanwhile, observability that lives entirely behind the CDN can go blind to the edge‑to‑origin gap where the failure lives.
For modern stacks, add three compounding realities:
- Shared fate at the edge. A small provider‑side misstep can impact many customers at once, and your operational state may be entangled with their control plane.
- As‑code everything. The same automation that saves toil can rapidly apply the wrong state globally. Safety rails matter more than cleverness.
- BYOIP is powerful—and sharp. Owning your prefixes grants portability and policy control, but you also inherit new failure modes when advertisement state drifts.
Cloudflare BYOIP outage: the questions teams keep asking
Was this a cyberattack?
No. The provider has stated clearly it was an internal change gone wrong, not a compromise. Treat it as a reliability lesson, not a security incident—though defense‑in‑depth still helps reduce blast radius.
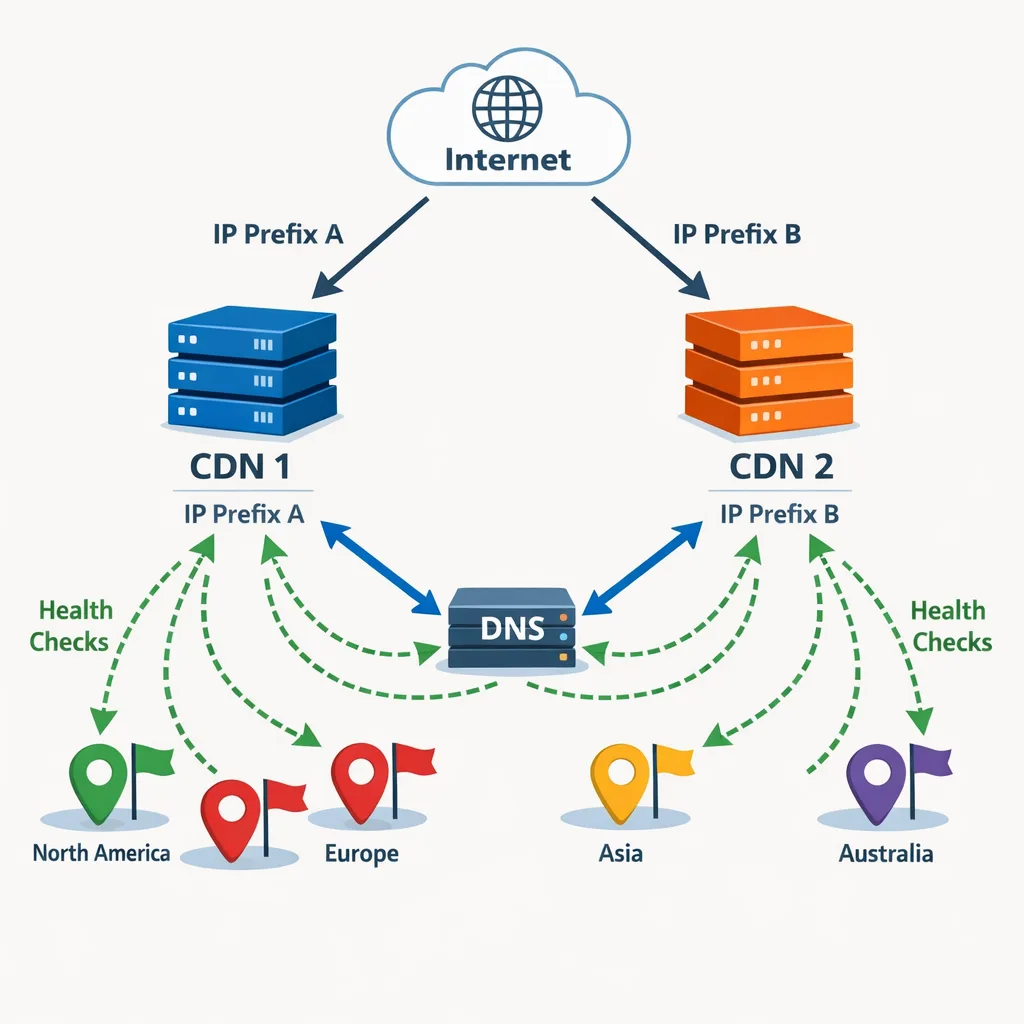
Would multi‑CDN have saved us?
It depends on architecture. If only one CDN advertises the affected prefixes, multi‑CDN in front of the same broken routes won’t help. If you can swing DNS‑ or IP‑level diversity (distinct ranges, distinct providers) with health‑based steering, you can shave minutes or hours off user impact. But multi‑CDN without IP diversity is false comfort.
Is BYOIP too risky?
Not inherently. BYOIP remains a great tool for portability and compliance. The risk isn’t BYOIP; it’s opaque state management and insufficient guardrails around BGP advertisements. Make the control plane observable and reversible.
A practical BYOIP resilience checklist
Use this to pressure‑test your setup this week. Assign names and dates to each item; don’t let it drift.
- Distinct ranges per provider. Advertise separate prefixes for Provider A and Provider B so one announcement mistake doesn’t sink both.
- Authoritative source of truth. Keep IP/prefix inventory in Git (or a database with versioned exports). Tie change tickets to commits. No snowflake config.
- Pre‑provisioned health‑based steering. Implement DNS steering or anycast alternatives that can swing traffic away when a prefix vanishes. Test with staged withdraws in non‑prod.
- Fast rollbacks for network state. Require that any “delete/withdraw” operation is trivially reversible. Scripts must support dry‑run, canary scope, and undo.
- Edge‑aware monitoring. Synthetic checks from 15+ geos to each advertised prefix, alongside Real User Monitoring (RUM) for connect and TLS times. Alert on connection timeouts, not only 5xx.
- Runbook ownership. Who triggers prefix re‑advertisement? Who pauses deploy pipelines? Who flips DNS steering? Put names, phones, and backups in the doc.
- Chaos drills. Practice prefix‑withdraw/restore in a sandbox each quarter. Record MTTD/MTTR and improve.
Design patterns that soften BGP‑level failure
1) Split horizon with IP diversity
Allocate at least two disjoint prefixes across two providers. Your primary advertises both; the secondary advertises one in warm standby. If the primary withdraws, the secondary announces the standby prefix and DNS steers new sessions there. It’s not perfect—existing TCP sessions may die—but you cap the outage window.
2) Anycast plus state decentralization
Anycast reduces localized failures, but it can hide global control‑plane regressions. Decentralize state: store sessions in client‑side tokens or regional stores replicated across providers. That way, failover doesn’t strand users mid‑transaction.
3) Tight change budgets for edge automation
Require canaries and progressive rollouts for anything touching advertisements, bindings, or address inventories. Default to “fail safe”: an empty or malformed filter should do nothing, not match everything. Add interlocks—human approvals or automated policy checks—for destructive operations.
4) Observability at the right layer
Watch the path users take, not just origin health. Ship lightweight synthetics from the public internet to each prefix and publish a one‑page internal “edge health” snapshot your on‑call can trust at a glance.
The 45‑minute incident drill (print this)
When routes disappear, time expands. This drill helps your on‑call compress the first 45 minutes.
- Minute 0–5 — Verify the layer. Check external synthetics and RUM for connection timeouts. If origin is green but connect/TLS times explode, suspect routing.
- Minute 5–10 — Check provider state fast. Status page, NOC feeds, and your Provider TAM/Slack channel. If BYOIP or advertisement issues appear, declare a network‑edge incident.
- Minute 10–15 — Attempt self‑remediation. Try re‑advertising affected prefixes per provider guidance. If bindings or configs look missing, don’t thrash. Escalate to provider while you proceed with step 4.
- Minute 15–30 — Shift traffic. Activate DNS steering to unaffected prefixes/providers. Reduce TTLs ahead of time so this sticks; if you didn’t, accept that propagation will be slower and start now.
- Minute 30–45 — Contain the blast. Pause deploys. Rate‑limit or degrade non‑critical features to preserve capacity for recovering paths. Communicate user‑visible status in plain language.
Then, when recovery begins, watch for the “half‑healed” state: advertisements look restored but bindings or egress policies lag. Keep synthetics pointed at the exact prefixes users hit.
Monitoring that would have shaved hours off
If you only watch 5xx at the origin, you’re late to the party. Aim for layered detection:
- Prefix‑scoped synthetics. ICMP/TCP/TLS checks to each advertised prefix from at least 15 geos. Alert on connect timeouts and median connect time spikes.
- RUM connect and TLS timings. Add fields for “connect_time” and “tls_handshake_time” to your beacon. Sudden climbs indicate path problems even when your origin is idle.
- Edge logs sampled to a shared timeline. If your provider exposes edge error codes (e.g., 403 “Edge IP Restricted” for specific endpoints), sample and chart them by prefix.
- External perspective. Keep at least one third‑party internet telemetry view (even if lightweight) to sanity‑check provider narratives while you triage.
Change management guardrails you can implement next sprint
This outage was a control‑plane mistake. The fastest wins live in how you change things:
- Schema‑first API checks. Any script touching advertisements must validate parameters against a typed schema. Empty strings and nulls should error loudly.
- Require dry‑runs and constrained filters. For destructive actions, block execution unless a scoped identifier set (prefix IDs) is provided and previewed with record counts.
- Make rollbacks cheap. Keep last‑known‑good advertisement state snapshots and a one‑click “restore” path. Store snapshots in object storage with immutable retention.
- Progressive rollouts and kill‑switches. Canary a tiny slice, validate health, then roll progressively. Maintain an operator kill‑switch that halts the worker or task runner instantly.
While you’re doing housekeeping, review other edge dependencies too. For example, Apple updated Xcode Cloud egress IP ranges on February 10, 2026. If your build systems or staging envs rely on IP allowlists, make sure they’re current—and consider dedicated egress controls. Our practical guide on egress firewalls for AI agents doubles as a good pattern for CI/CD and edge services.
Policy and architecture notes for leaders
Zooming out, I’d set expectations like this with executives and product owners:
- Target “hours, not days.” When a provider‑side routing issue hits, your control window is minutes. Your runbooks and DNS steering decide whether the user‑visible outage is 10 minutes or 2 hours.
- Invest in portability where it matters. BYOIP, multiple regions, and multi‑provider delivery pay off when your revenue is highly session‑sensitive (checkout, auth, live events). Don’t over‑engineer brochure sites.
- Publish a one‑page “Edge Architecture” doc. Show the prefixes, providers, steering logic, and who owns what. Keep it evergreen.
Case study: how a product team can tighten up in 2 weeks
Here’s a pragmatic plan I’ve run with platform teams after similar incidents:
- Week 1: Inventory prefixes and providers; implement or fix prefix‑scoped synthetics; draft the 45‑minute drill; set DNS TTLs to 60–120s for critical hostnames; rehearse one failover.
- Week 2: Split at least one high‑value service onto a second provider with a distinct standby prefix; introduce dry‑run + canary to any edge automation; add a rollback snapshot job nightly.
By the end of two weeks you won’t be invincible, but you’ll be meaningfully more resilient to control‑plane accidents.
What to do next
- Run the 45‑minute drill with your on‑call and record times. Fix the slowest step immediately.
- Stand up prefix‑scoped synthetics and RUM connect/TLS metrics. Alert on timeouts, not just 5xx.
- Split one critical service onto a second provider with a distinct prefix; wire up DNS steering.
- Require dry‑run + canary + rollback snapshots for any script that touches advertisements.
- Document owner, pager, and TAM contacts in your runbook; store a local copy offline.
Further reading and help
If you’re modernizing your delivery stack, a few resources from our team can accelerate the work: a zero‑downtime approach in our Vercel migration playbook, edge egress patterns in Egress Firewalls for AI Agents, and operational upgrade cadence in Node.js EOL: Your 45‑Day Upgrade Playbook. If you want hands‑on help designing multi‑provider delivery or BYOIP runbooks, explore our services or tell us about your stack via our contact form. We ship quietly, test relentlessly, and measure the right things.

Bottom line
The February 20 routing incident wasn’t exotic—it was the predictable consequence of powerful automation meeting inadequate guardrails. The fix isn’t abandoning BYOIP or edge networks; it’s treating the control plane as production code with type checks, canaries, and rollbacks, and pairing that discipline with genuine IP diversity and path‑aware monitoring. Do that, and the next time a provider trips, your users might not even notice.








Comments
Be the first to comment.