Egress Firewalls for AI Agents: A Practical Playbook
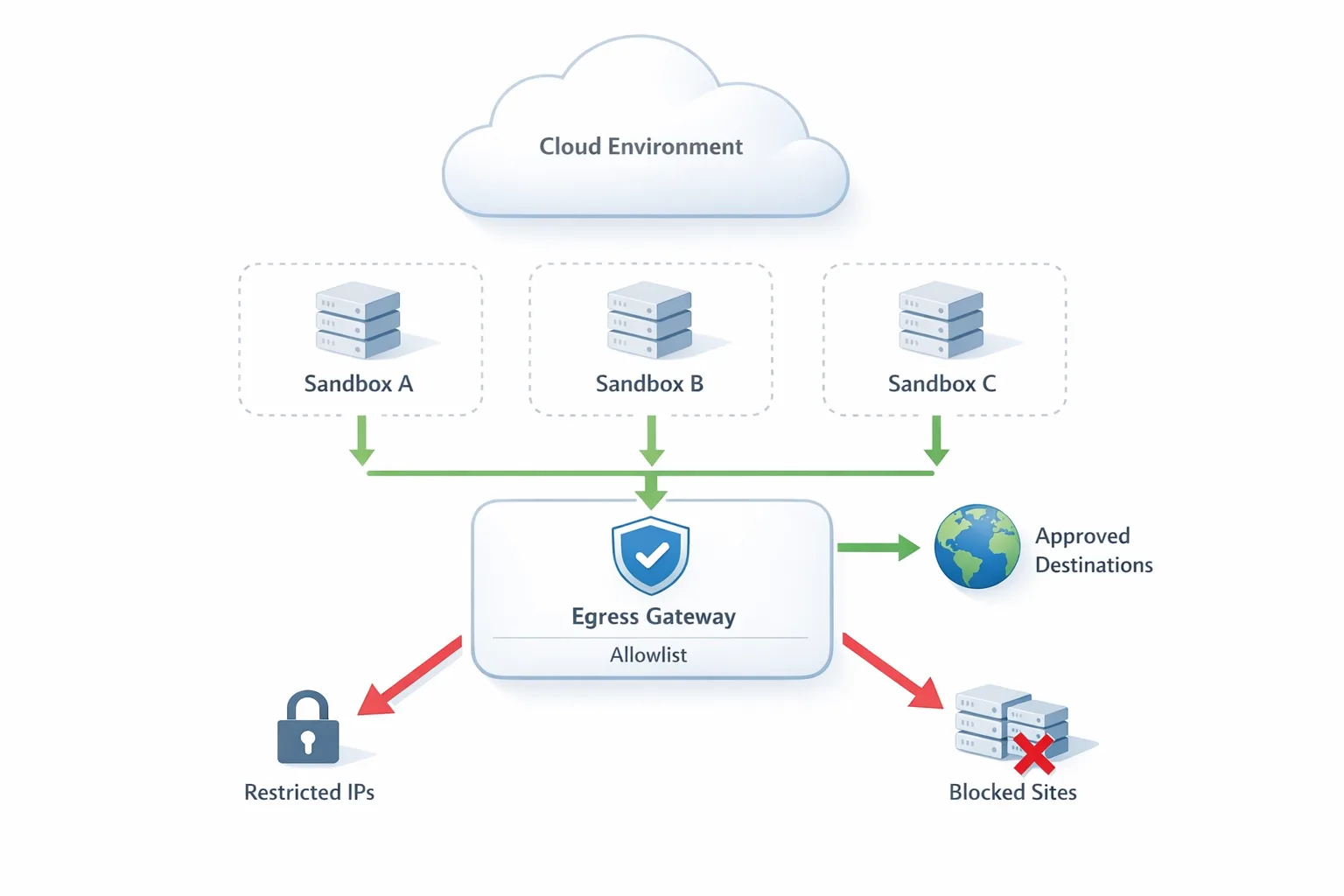
The primary job of an egress firewall is dead simple: stop anything inside your environment from talking to the outside world unless it’s explicitly allowed. In 2026, that control moved from “nice to have” to the default posture for teams running AI agents, serverless sandboxes, and code execution features. Here’s the thing—outbound is where accidental data leaks and supply‑chain surprises actually happen. If you let agents or untrusted jobs dial any host on the internet, you’re gambling with customer data, API keys, and your incident budget.
Why now: AI agents, ephemeral compute, and a shrinking blast radius
Developers ship more untrusted code than ever: agent-generated scripts, user-submitted plugins, and build-time tasks running in ephemeral VMs. Those workloads are powerful precisely because they can fetch models, pull packages, hit third‑party APIs, and transform data in motion. But there’s a catch—every outbound dial is also a potential exfiltration path. Over the last few weeks, major platform vendors have rolled out first‑class outbound controls—think host‑based allowlists via Server Name Indication (SNI), explicit CIDR ranges, and toggles you can change at runtime without restarting sandboxes. Translation: you no longer need clunky proxies or brittle IP pinning to get real protection.
That change is timely. AI features land faster than governance, and security teams can’t manually pre‑review every outbound call an agent might attempt. Egress policy gives you a single, auditable switch: approved hosts only, everything else fails fast. Done well, this even improves reliability—no mystery calls, fewer DNS surprises, cleaner deploys.
The basics: what an egress firewall is (and isn’t)
Think of inbound as the castle gate and outbound as the courier leaving with your secrets. An egress firewall:
- Evaluates outbound traffic from apps, jobs, and sandboxes.
- Enforces least‑privilege access to specific destinations (hosts, ports, sometimes paths).
- Rejects unauthorized connections before data crosses the wire (for TLS, at handshake via SNI matching).
What it’s not:
- It’s not a web proxy that rewrites content or caches responses.
- It’s not a DLP silver bullet. It reduces the places data can go; it doesn’t classify the data for you.
- It’s not a substitute for secrets hygiene or runtime isolation; it works with those controls.
Five sneaky exfiltration paths you’re probably missing
Before we get practical, let’s surface the patterns that bite teams during rollout:
- Package managers to anywhere: npm, pip, and friends pulling from arbitrary mirrors, registries, and Git URLs.
- Dependency post‑install scripts: Unexpected network calls fired during install, build, or test hooks.
- Webhook callbacks: Third‑party services that need to reach you but also require you to call them (two‑way trust).
- Update checkers and telemetry: CLI tools that phone home; not malicious, just unexpected.
- “Helpful” auto‑discovery: SDKs that probe multiple endpoints until one responds (S3‑style region discovery, OAuth well‑known URLs, etc.).
Rollout, not rip‑and‑replace: a no‑drama egress firewall plan
Here’s a playbook we’ve used with product teams moving fast and carrying sharp objects. It’s incremental, testable, and measurable.
1) Map data, then the hosts that must see it
Start with your sensitive data domains: customer PII, payment tokens, internal API responses, production DB snapshots. For each, list the destinations that legitimately need access. Example: “Customer PII can leave only to Stripe, our email provider’s inbound API, and our CRM ingestion endpoint.” Avoid long abstract threat models; list concrete hosts.
2) Discover real traffic before you block
Turn on passive discovery for a week in pre‑prod. Capture egress hostnames, not just IPs. Group by service and phase (build, test, runtime). Expect surprises: package registries, time servers, license checks, and forgotten webhooks. Keep track of port numbers too; you’ll use them to tune allowlists later.
3) Build a starter allowlist with SNI + CIDR
Create host allowlists for the services you actually use (api.openai.com, files.stripe.com, your‑company.scm.host), and CIDR rules only where endpoints truly don’t present meaningful hostnames. For package managers, prefer vendor‑hosted registries or your internal mirror, not “the entire internet.”
4) Stage policies: monitor → fail‑closed for one path
Flip to monitor‑only first and measure what would have been blocked. When the signal looks clean, choose a narrow surface to lock: example, ephemeral sandboxes running AI agent tools. Make that path fail‑closed (deny by default). Roll out to 10%, then 50%, then 100% over a few days.
5) Fix the two big friction points: packages and webhooks
Point npm/pip to a known registry (registry.npmjs.org or your cache) and block Git+SSH installs unless reviewed. For webhooks, standardize on outbound calls to a small set of vendor domains, and document expected ports and retries. Where a vendor offers region‑pinning, use it.
6) Protect secrets like they will leak anyway
Assume a key will end up in an agent prompt or build log. Scope tokens to allowlisted destinations only, rotate automatically, and store them in a managed vault. If your platform supports automatic secret scanning and revocation for exposed tokens, turn it on today.
7) Make it observable
Ship logs for allow/deny events with request metadata (sandbox ID, service, hostname, port). Create a weekly report: new hosts requested, top denies, mean time to approve, and the “shadow traffic” you eliminated. In exec terms, this is your proof of risk reduction, not just a policy change.
Implementation notes: sandboxes, serverless, and Kubernetes
The exact mechanics vary by stack, but the principles rhyme. Below are pragmatic pointers you can apply this week.
Ephemeral sandboxes and microVMs
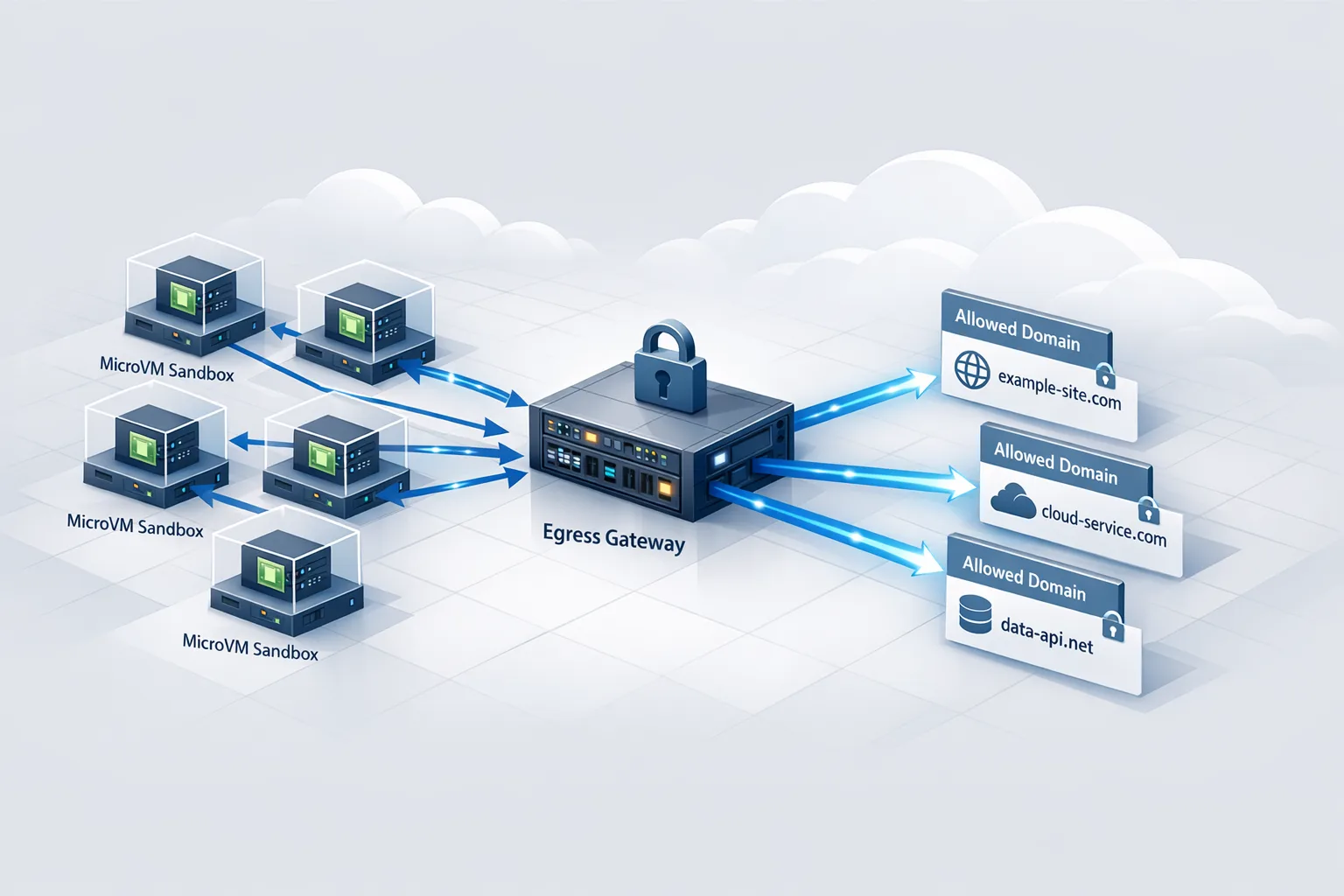
Many teams now evaluate agent‑generated code inside short‑lived sandboxes. The sweet spot here is runtime‑tunable egress: start in allow‑all while you fetch inputs, then flip to deny‑by‑default for execution, with an allowlist of the 2–5 hosts the task truly needs. Modern sandboxes support host‑based filtering at TLS handshake using SNI, plus CIDR for services that don’t surface useful hostnames. That lets you stop unauthorized connections before any payload leaves the VM.
Serverless functions and edge runtimes
Serverless breaks the old “appliance firewall” model. Put egress policy in the platform or at a centralized, low‑latency egress gateway. Keep the rule count short and understandable—by humans. When you pin outbound calls to named hosts instead of raw IPs, your policies survive CDN shuffles and cloud provider migrations.
Kubernetes
NetworkPolicies and egress gateways work well, but be honest about complexity. Keep a dedicated egress namespace with policy ownership in platform engineering, not buried in each app repo. Use labels to group workloads that share a policy (e.g., “prod‑ai‑agents”). For package installs in CI jobs, give them a distinct policy with a separate, narrower allowlist than runtime services.
People also ask
What’s the difference between an egress firewall and a proxy?
A proxy intermediates and can modify traffic; an egress firewall simply decides “allowed or blocked” by destination (hostname, port, IP/CIDR). You can chain them, but don’t let the proxy become a loophole—its upstream must still be bound by your egress rules.
Will an egress firewall break package installs and webhooks?
It can if you don’t prepare. Solve packages by pinning to a small set of registries or an internal cache. Solve webhooks by listing the specific vendor domains you call and documenting ports/timeouts. Most breakage comes from surprise network calls during post‑install scripts—catch those in discovery before enforcement.
How do I test outbound policies in CI without blocking my whole org?
Run the policy in monitor for your CI namespace and fail the job on a deny event instead of dropping the packet. Your developers get fast feedback, your platform logs build a clean allowlist, and you can flip to hard enforcement when the noise is gone.
The two big levers: SNI allowlists and CIDR the right way
Host‑based allowlists using SNI are the most resilient control for TLS traffic. They match the hostname the client intends to reach before encryption kicks in. Use this wherever possible: public APIs, SaaS endpoints, package registries, and your own services behind a stable domain. Reserve CIDR rules for cases that genuinely need them: private peering, static vendor IPs, or services without stable hostnames. And document every CIDR rule with an owner and an expiry review date; otherwise they turn into forever holes.
A field‑tested worksheet you can copy
Grab a whiteboard or a doc and fill this in for each workload:
- Purpose: What business task does this workload perform?
- Data in scope: List the sensitive types it can touch.
- Allowed hosts: Hostname, port, protocol, and why it’s needed.
- Package policy: Which registries/mirrors are permitted?
- Secrets: Which tokens are required, with scopes tied to those hosts?
- Observability: What logs/metrics prove it’s working?
- Owner + review date: Who approves changes, when do we re‑review?
Do this for your top three high‑risk paths first: AI agent sandboxes, CI jobs that run user‑supplied tests or plugins, and anything that transforms production data outside your core app.
Risk, cost, and speed: how to measure the win
Executives don’t buy firewalls, they buy outcomes. Track a small set of metrics that show real movement:
- Block rate trend: Denied connection attempts per 1,000 requests (should drop as your allowlist stabilizes).
- Mean time to approve: How long from first deny to policy update in production.
- Shadow traffic eliminated: Number of previously unknown hosts removed from builds/tests.
- Incident proxies: Fewer “mystery host” entries in post‑mortems over a quarter.
On cost: a clean allowlist reduces churn. You spend fewer cycles on flaky CI (random mirrors, rate‑limited endpoints) and fewer emergency vendor calls during outages. Most teams report neutral or positive performance impact because failed connections die early at handshake instead of hanging for seconds.
Integrating flags and staged rollouts
Feature flags pair well with egress policy. Ship a “strict egress” flag for your sandboxes and flip it on for 10% of jobs, then ramp. If you’re already using a platform‑level flags product, you can wire policy shifts to the same workflow you use for gradual API launches. For a deeper dive into orchestrating progressive security changes alongside product releases, see our take on shipping safer with flags and sandbox egress.
Playbook example: locking down an AI code runner in a week
Let’s get practical. Say you offer an in‑browser IDE that runs user code in an ephemeral sandbox:
- Day 1–2: Turn on discovery and record outbound hostnames for code runs. You’ll see registries, a handful of public APIs, and maybe cloud storage.
- Day 3: Draft the allowlist: package registry host, your storage domain, and two public APIs. Everything else is blocked.
- Day 4: Enforce for non‑paid traffic first (or a subset of orgs) and watch denies. Fix legitimate misses by adding explicit hosts, not wildcards.
- Day 5–7: Roll to 50%, then 100%. Add runtime toggles so you can temporarily open a host for a specific job, then lock it again.
The output is a smaller blast radius: even if an agent “hallucinates” a call to a random domain, the connection dies harmlessly and you get a clear log of what it attempted.
Common pitfalls and how to dodge them
Wildcard fatigue: Don’t add *.vendor.com unless the vendor confirms subdomains are stable and limited. Prefer the exact API or upload hostnames.
IP pinning without a plan: CDNs change IPs. If you must use CIDR, get written ranges and monitor for drift. Set a quarterly review.
One policy to rule them all: Different phases need different rules. Builds should reach registries; runtime shouldn’t.
Silent failures: Failing closed is the goal, but make it noisy in the right places. Bubble deny reasons to logs and dashboards your devs actually check.
What to do next
- Pick one high‑risk path (AI sandboxes, CI plugins) and run a one‑week discovery.
- Draft a 5–10 host allowlist using SNI, with CIDR only when you must.
- Stage enforcement with a flag and a 10% canary, then ramp.
- Pin your package sources and document webhook domains and ports.
- Wire deny logs to a simple weekly report and review it with engineering leads.
Where we can help
If you want guidance on staging egress policies without breaking velocity, our team has shipped this pattern for startups and scale‑ups. Explore our security and platform services, see a few of the projects we’ve delivered in our portfolio, and keep an eye on our blog for hands‑on migration playbooks across mobile and web. If you’re staring at a complex rollout or need help designing an allowlist that won’t crumble next quarter, talk to us—we’ll meet you where your stack is today.

Zooming out
Security teams used to argue about deep packet inspection versus behavioral analytics while outbound traffic sailed past. The shift to strong, host‑based egress controls flips that story. You stop hand‑wringing and start shipping: one meaningful control, enforced early in the connection, with a tight feedback loop to improve it. That’s the kind of guardrail that lets AI features grow up without growing your incident queue. Put the egress firewall in place, prove you didn’t break the build, and get back to building the thing your customers care about.





Comments
Be the first to comment.