
GitHub Actions Self‑Hosted Runner Pricing: What to Do Now
GitHub Actions self-hosted runner pricing arrives on March 1, 2026. The new $0.002 per‑minute platform fee applies to jobs that run on your own hardware in private or internal repositories, while public repos remain free to run. There’s a second deadline, too: starting March 16, 2026, GitHub will block configurations using self‑hosted runner versions older than v2.329.0. If Actions underpins your delivery pipeline, now’s the time to get intentional about minutes, autoscaling, and security.
GitHub Actions self‑hosted runner pricing: what’s changing and when
Two concrete dates matter:
• January 1, 2026: GitHub updated pricing for GitHub‑hosted runners and introduced a platform charge baked into those listed per‑minute rates. Public repos are still free on standard runners.
• March 1, 2026: Self‑hosted jobs in private or internal repos start incurring a $0.002 per‑minute platform fee. You still pay your own compute costs separately (cloud, on‑prem, or bare metal). Enterprise Server customers aren’t affected by this cloud platform charge.
• March 16, 2026: Minimum version enforcement for self‑hosted runners goes live. Any runner older than v2.329.0 will be blocked from executing jobs. Plan your upgrades with change windows and rollbacks to avoid stalled pipelines.
Here’s the thing: the fee is small on paper, but it shines a floodlight on pipeline waste. If your organization burns millions of minutes each month on self‑hosted capacity, even tiny per‑minute costs become line items leadership will question.
How much will this cost my team?
Let’s model a few realistic scenarios. The fee is simple: minutes × $0.002. That’s $2 per 1,000 minutes.
• A mid‑sized team running 50,000 self‑hosted minutes per month will pay about $100.
• A larger org burning 1,500,000 minutes monthly (common with monorepos and big matrices) will pay about $3,000.
• Spiky GPU or macOS workloads that offload to self‑hosted hardware can rack up 250,000 minutes in a heavy release month—roughly $500.
The platform fee doesn’t include artifact or cache storage costs, nor your runner infrastructure bill. But it does force a conversation: do we need to run this job on self‑hosted capacity at all, and if so, can we make it faster?
Why GitHub is doing this (and what it means for you)
GitHub framed the change as aligning platform costs with usage while investing more into the self‑hosted ecosystem: better autoscaling (beyond Kubernetes), multi‑label support for ARC and the new Scale Set Client, and beefed‑up reliability. Translation for practitioners: expect steadier job queuing, simpler autoscaling options that don’t require owning a K8s control plane, and more predictable runner fleet management. The price pressure is real, but the potential operational upside is, too.
The practical framework: Reduce, Rehost, Replatform, and Reinforce
Use this four‑part plan to adapt quickly without breaking delivery.
1) Reduce minutes: cut what doesn’t ship value
Start with ruthless hygiene. You’ll recover 15–40% of minutes in most orgs within two weeks:
• Tighten path filters: Only run workflows on files that matter. Skip docs and non‑code changes for test and build jobs.
• Cancel in‑progress on supersedes: Use concurrency with cancel-in-progress: true for PR checks to avoid piling up obsolete runs when developers push multiple times.
• Right‑size matrices: Parameterize and prune OS, runtime, and device matrices. Keep full matrices on nightly schedules; use smoke subsets on PRs.
• Cache with intent: Cache dependency layers that are stable by version (e.g., key: ${{ runner.os }}-node-${{ hashFiles('pnpm-lock.yaml') }}). Don’t cache build outputs that change frequently and thrash your cache store.
• Parallelize tests intelligently: Use sharding at the test framework level, not job‑level duplication, to minimize setup time per shard.
• Gate expensive jobs: Only run end‑to‑end or device lab tests on labeled PRs or after approvals.
2) Rehost jobs where it’s cheaper or simpler
Not every job belongs on self‑hosted capacity. Ask three questions:
• Does the job need special hardware (macOS, GPUs, exotic drivers)? If not, benchmark it on a GitHub‑hosted runner and compare total cost, including your platform fee and ops time.
• Is the job I/O‑bound and benefits from fast hosted caches? Today’s hosted runners often win on artifact and cache throughput.
• Is isolation the priority? Hosted runners are fully ephemeral VMs by default. If you’re carrying bespoke hardening on self‑hosted VMs just for isolation, you may be reinventing the wheel.
3) Replatform your self‑hosted fleet for elasticity
If you keep self‑hosted (many should), make it elastic and ephemeral. You’ll reduce idle minutes, speed up cold starts, and slam the door on lateral movement risks.
• Adopt autoscaling: Use Actions Runner Controller (ARC) if you already run Kubernetes, or try GitHub’s Scale Set Client for VM‑based fleets without K8s. Both approaches support multi‑label setups, so a single ephemeral instance can satisfy several workflows.
• Bake golden images: Preload toolchains and SDKs (Xcode, NDK, CUDA, browsers) into AMIs or VM templates. The fastest minute is the one you never spend on provisioning.
• Default to ephemeral: Prefer short‑lived instances that register on boot and are destroyed after a job. Persist only what must live (private package mirrors, remote caches).
• Instrument queue depth and time‑to‑start: Auto‑scale on queue length, not just CPU. Your SLA is build start time, not utilization.
4) Reinforce security and governance
New fees mean new scrutiny. Use the moment to close gaps you’ve tolerated:
• Pin runner versions and labels: With minimum version enforcement on March 16, 2026, standardize on v2.329.0+ and audit labels to prevent jobs from landing on stale hosts.
• Isolate networks: Put self‑hosted runners in dedicated subnets with egress controls. If your runners fetch model weights or call vendor APIs, see our egress firewall playbook for AI agents to borrow patterns that also fit CI.
• Rotate secrets and tokens: Treat runners as disposable. Short‑lived OIDC credentials and scoped tokens reduce blast radius.
• Log everything that matters: Correlate job IDs, runner instance IDs, and cloud instance metadata. This is non‑negotiable for incident response.
Upgrade checklist before March 16 (don’t get blocked)
You have a hard requirement to run self‑hosted runners at v2.329.0 or later by March 16, 2026. Here’s a quick, reliable path:
• Inventory: List every repository, org, and environment that references self‑hosted runners. Don’t forget ephemeral pools and scale‑set machines.
• Stage rollout: Upgrade non‑prod fleets first, then canary 10–20% of prod capacity during a low‑traffic window.
• Health gates: Validate runner registration, labels, and tool availability with a tiny workflow that fails loud on missing prerequisites.
• Rollback plan: Keep the prior image for 72 hours and retain the ability to pin jobs to known‑good labels while you triage.
• Deadline drill: Simulate the enforcement by temporarily blocking older versions in your org policy to see what breaks.
Patterns that pay back in weeks
Teams that treat this change as a tune‑up see quick wins. These patterns are boring—in the best way:
• Split your monolith pipeline: Separate lint/unit from build/e2e and deploy each on the right capacity. Most PRs only need the first stage.
• Precompute SDK layers: If you ship iOS or Android, publish Xcode/NDK layers to an internal registry and pull them into ephemeral runners at launch. It’s routine to save 5–10 minutes per job.
• Use a single source of truth for versions: A repo‑wide tool-versions file (asdf or similar) prevents tool churn between runner images and developer machines.
• Adopt concurrency budgets: Cap PR concurrency per repo to prevent thundering herds when a large team rebases at once.
People also ask
Do public repositories pay the new fee?
No. Standard GitHub‑hosted runner minutes are still free for public repositories. The new platform fee targets self‑hosted usage in private or internal repos on GitHub.com.
Does queued time count toward minutes?
No. You pay for execution time. Queued or waiting time isn’t billed in the platform fee.
We run GitHub Enterprise Server on‑prem. Are we impacted?
No. The new cloud platform fee is specific to GitHub.com Actions. Your on‑prem GitHub Enterprise Server instance is outside this change.
Should we move everything back to GitHub‑hosted runners?
Probably not. If you need macOS, GPUs, special drivers, or network access to internal systems, self‑hosted still makes sense. But re‑benchmark generic workloads on hosted runners—they’re faster than many teams assume.
A simple cost worksheet you can copy
To bring clarity to finance and engineering in the same meeting, build this one‑pager per workload:
• Workload: “Mobile build and sign (iOS)”
• Current placement: self‑hosted (macOS AMIs on AWS)
• Minutes/month: 120,000
• New platform fee: $240/month
• Infra cost: $2,950/month (3 M2 Pro instances, spot blended)
• Alternatives considered: GitHub‑hosted macOS XL (estimate $X), hybrid (hosted for PRs, self‑hosted for nightly and release)
• Decision (date): Hybrid; target 60% minutes on hosted by April 30, 2026
Repeat per top workflow. You’ll find at least one that belongs on hosted runners and one that demands deeper optimization.
Security corner: ephemerality and egress matter
Long‑lived runners drift. They accumulate caches, custom scripts, and sometimes credentials they shouldn’t have. Moving to ephemeral, autoscaled runners fixes a class of problems in one move. Pair that with egress restrictions—CIDR allowlists to registries, artifact stores, signing services—and you’ll stop whole categories of supply‑chain risk at the firewall. If you’re building AI features or integrating external APIs, our practical egress controls guide has patterns you can lift straight into CI networks.
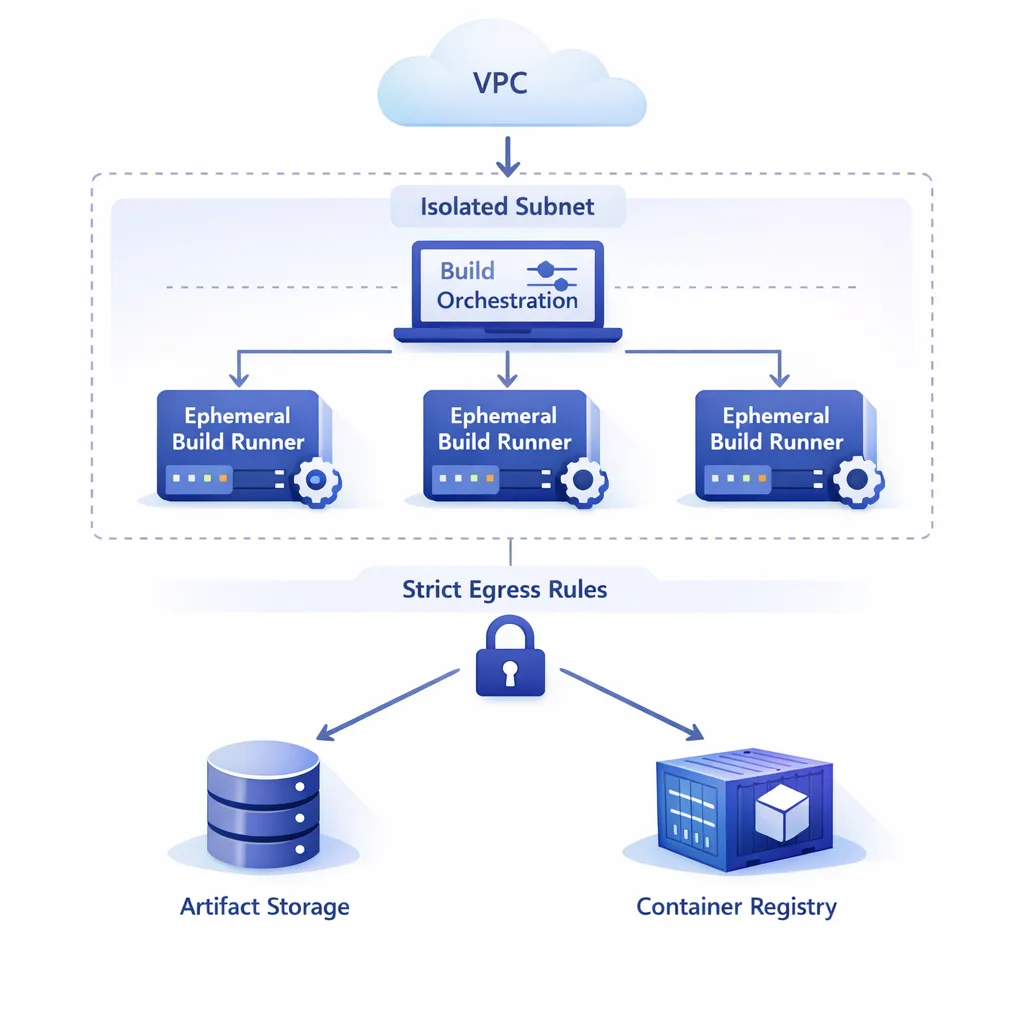
Modernizing your fleet: ARC vs. Scale Set Client (quick take)
• ARC (Kubernetes): Best if you already operate K8s. Mature autoscaling, familiar primitives, and the ability to run many ephemeral pods per node. Complexity lives where your team already has skills.
• Scale Set Client (VM‑based): Best if you don’t want Kubernetes. It manages job queuing and labels and works with your favorite cloud VMs or on‑prem virtualization. Less moving pieces, easier to onboard infra‑light teams.
Either way, aim for immutable images and treat runner hosts as cattle, not pets. Build packs with Packer, Image Builder, or cloud‑native tooling. Bake in your observability agent and OS hardening. Keep the job surface area small; pull test data on demand; push artifacts out quickly.
What to do next (this week and next month)
Here’s a short execution plan you can run with immediately:
Week 1
• Inventory minutes by workflow and repo. Sort top‑10 consumers.
• Enable concurrency cancel‑in‑progress on PR checks.
• Add path filters to skip jobs on non‑code changes.
• Stand up a canary pool on v2.329.0 and validate labels.
Week 2–3
• Convert one heavy workflow to ephemeral autoscaled runners.
• Bake a golden image for your heaviest toolchain (Xcode, NDK, CUDA).
• Move generic jobs to GitHub‑hosted runners and compare cost/perf.
• Lock down egress for runner subnets and rotate tokens.
Week 4–6
• Finish the fleet upgrade to v2.329.0+ before March 16, 2026.
• Roll out shard‑aware test parallelism and shrink matrices on PRs.
• Present your finance worksheet and finalize a hosted vs. self‑hosted split for Q2.
Need a partner?
If you want hands‑on help building ephemeral runners, benchmarking hosted vs. self‑hosted, or cutting minutes without slowing developers, our team does this weekly. Explore our CI/CD modernization services, see how we ship for clients in the portfolio, or get a tailored plan in our recent note on a March 2026 self‑hosted runner plan. Prefer to start with a quick conversation? Contact us—we’ll share a one‑page worksheet you can adapt in an hour.

Zooming out
Pricing changes are always uncomfortable, but this one’s also useful pressure. The new fee doesn’t just add cost—it exposes where your delivery system is slow, fragile, or over‑engineered. Tighten your triggers, go ephemeral, and shift work to the right place. By the time the invoice arrives, you’ll be running leaner pipelines with cleaner security—and you’ll have the data to defend every minute you still spend.








Comments
Be the first to comment.