Mini Shai‑Hulud: npm Supply Chain Attack—What to Fix Now
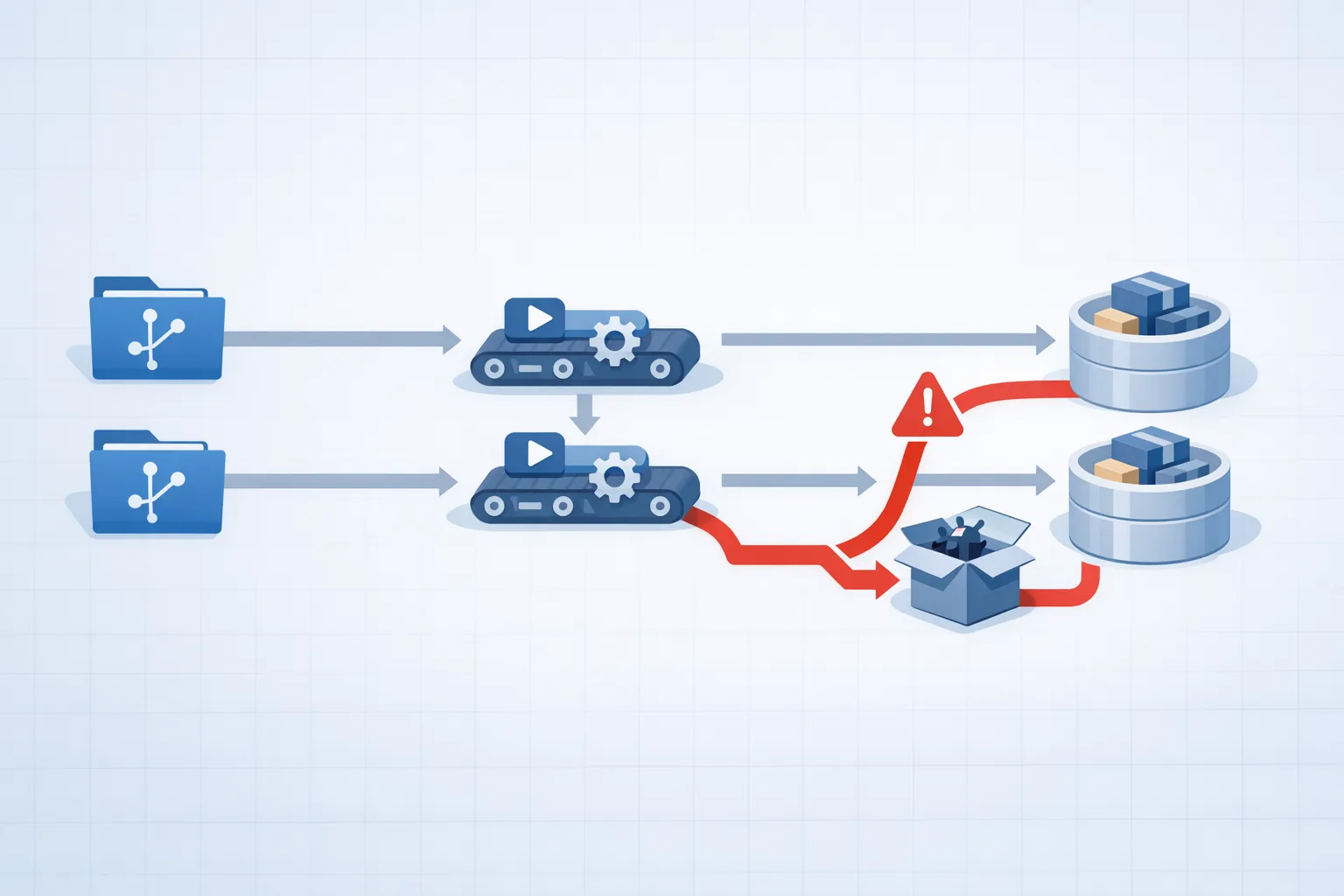
The latest npm supply chain attack isn’t theoretical. Between May 11 and May 12, 2026, the “Mini Shai‑Hulud” campaign pushed malicious versions of popular packages, including dozens across the TanStack ecosystem on npm and the mistralai 2.4.6 client on PyPI. At least one major AI vendor acknowledged two affected employee devices and is rotating code‑signing certificates on a hard deadline in June. If your developers or CI pulled updates during those windows, treat the host as compromised and your secrets as exposed.
What actually happened (and when)
Here’s the short version, grounded in what maintainers and vendors have publicly confirmed. On May 11, 2026 (around 19:20 UTC), attackers published 80+ malicious TanStack versions in minutes. Payloads executed during installation and attempted to exfiltrate GitHub, npm, cloud, and SSH credentials from developer machines and CI runners. Within hours, additional packages showed similar behavior. Early May 12, 2026, mistralai==2.4.6 on PyPI briefly contained import‑time malware (Linux‑only) that dropped and executed a secondary payload. Maintainers pulled and replaced compromised artifacts the same day, and advisories listed indicators and version ranges to check.
Two operational details matter for your response: first, some of the npm payloads executed during the npm install lifecycle (pre/post scripts and embedded files), which means merely installing an affected version could leak secrets available to that process. Second, at least one Python package executed code at import, so tests, local experimentation, or notebooks could have triggered it even without a full deployment.
Am I affected by the Mini Shai‑Hulud incident?
Ask three questions in this order:
- Did any machine (developer workstation, ephemeral CI, or long‑lived runner) perform a dependency install of affected npm packages on May 11–12, 2026, or import
mistralai==2.4.6from PyPI? - Were long‑lived secrets reachable from that process? Think GitHub tokens, npm tokens, cloud credentials, SSH keys, container registry logins, or cookie‑like session artifacts.
- Do your logs or EDR show network calls to unusual hosts immediately after install/import, or traces of temporary files and services commonly named by the IOCs shared in advisories?
If the answer to #1 is “yes” or “unknown,” assume compromise. Unknown usually means “we didn’t centralize dependency telemetry,” which is itself a fixable gap.
Quick triage: a 72‑hour incident plan for JS/Python shops
Here’s a concise plan you can execute without grinding delivery to a halt.
0–8 hours: Contain
- Freeze builds: pause non‑critical CI pipelines and automated dependency updates. Stop the bleeding first.
- Quarantine suspected hosts: segment affected developer machines and any CI runners that installed malicious versions. Snapshot for later forensics.
- Revoke and rotate: immediately rotate GitHub personal access tokens, organization secrets, npm tokens, and cloud keys accessed by quarantined hosts. In clouds, prefer short‑lived role tokens over long‑lived keys when you reissue.
- Invalidate sessions: sign everyone out of VCS and package registries org‑wide. Force re‑auth with MFA.
8–24 hours: Verify and eradicate
- Hunt IOCs: look for unusual outbound connections made during installs/imports, suspicious temp files in
/tmpon Linux and equivalent temp paths on other OSes, and any spawned background services tied to the payload timeline. - Reimage long‑lived runners: don’t argue with the clock—wipe and rebuild them from golden images. For developer machines, wipe or bare‑metal reinstall if any credential material may have been exposed.
- Lock registry mirrors: configure npm and PyPI mirrors with a “minimum package age” (24–72 hours) so fresh versions can’t auto‑land in prod before community scrutiny.
- Pin and verify: enforce lockfiles and integrity checks. Verify signatures or provenance for critical packages; fail closed if verification is missing.
24–72 hours: Recover and harden
- Secret provenance audit: map where each rotated secret is used (apps, infra, CI). Remove unused secrets and scope the rest to least privilege.
- CI isolation: run untrusted code paths in separate runners without org‑wide tokens, disable
pull_request_targetpatterns, and nuke cross‑repo caches. - Ship a dependency SBOM: snapshot a bill of materials for your apps and services this week so you can answer “Are we affected?” in minutes next time.
- Tabletop the next one: run a 60‑minute drill using this incident’s timeline and your own package list. Close the slowest decision points first.
How the attack chain worked (plain English)
Attackers abused project release automation and package lifecycle behaviors—not novel bugs in the frameworks themselves. In multiple npm packages, the malicious payload executed during npm install using a combination of lifecycle scripts and embedded files. Once running, it enumerated and exfiltrated secrets it could reach: local SSH keys, GitHub tokens, npm tokens, and cloud credentials. On the Python side, the compromised client executed code when the package was imported (Linux‑only), dropped a secondary payload in a temp directory, and attempted persistence or command execution.
Why did this work? Because build and install steps in modern toolchains routinely have access to powerful tokens, and because automated release pipelines can be tricked into trusting artifacts they didn’t fully control. This is the same recurring lesson from past incidents: the weakest link isn’t a missing semicolon in your app—it’s the trust boundary around your CI and registries.
The npm supply chain attack: a checklist to ship safely
Here’s a pragmatic checklist you can apply today. It assumes you use npm, maybe PyPI, GitHub Actions, and at least one cloud.
- Quarantine fresh packages. Enforce a minimum publish age before consumption (I like 48 hours) via your internal registry or policy engine. It buys the community time to spot bad releases.
- Pin everything. Use
package-lock.json/pnpm-lock.yaml/yarn.lockandpip-tools/poetry.lock. Fail builds on lockfile drift outside an intentional update PR. - Verify provenance. Require Sigstore/SLSA provenance for critical packages where available. If your org publishes packages, sign them and publish attestations.
- Kill install scripts by default. In CI, set
npm_config_ignore_scripts=trueexcept for allow‑listed packages you control. - Segregate CI trust zones. Run PRs from forks in isolated runners with no org secrets. Disable
pull_request_targetunless you really understand it and have compensating controls. - Harden caches. Don’t share package or build caches across trust boundaries. Scope caches per repo and workflow. Expire aggressively and pin by exact content hash.
- Move to short‑lived credentials. Prefer OIDC‑based, audience‑bound tokens in cloud and registry workflows. Set maximum lifetimes to minutes, not days.
- Scan behavior, not just CVEs. Pair
npm audit/pip auditwith tools that detect suspicious package behavior: new network calls, filesystem writes, environment reads, and obfuscated blobs. - Instrument dependency installs. Centralize logs for
npm/pipruns (command, user, versions, hashes, durations, network). You cannot respond fast if you can’t answer “who installed what, when.” - Golden images > pets. Build immutable runner images. If something looks off, replace, don’t nurse.
People also ask
Do lockfiles protect me from this kind of attack?
They help, but they aren’t a silver bullet. If your lockfile points to a compromised version, your installer will faithfully fetch it. The real value of lockfiles is stability: you know exactly which version you pulled, which makes triage faster and rollback cleaner.
Should we wipe our CI runners if they installed a bad version?
If the runner was long‑lived or had persistent volumes and secrets, yes—rebuild from a trusted image. For ephemeral runners that were truly isolated and had no sensitive tokens, a fresh instance is usually sufficient. When in doubt, replace.
Are developer machines at risk if we only ran tests?
Possibly. Some payloads ran at install time; a Python payload executed on import. If a test or notebook imported the compromised package, secrets on that host may have been exposed. Treat the system as suspect, rotate tokens, and consider a full wipe.
Should we stop using npm or PyPI?
No. You should stop using them without guardrails. Mature teams treat public registries as untrusted sources behind controlled mirrors, delayed ingestion, provenance checks, and install‑script blocks in CI.
Let’s get practical: a 9‑control baseline that sticks
I’ve implemented or audited all of these in production teams; they meaningfully cut risk without wrecking developer flow.
- Registry gateway with policy. Route npm/PyPI through an internal proxy that enforces minimum age, allow‑lists, and provenance. Surface a manual override for urgent hotfixes.
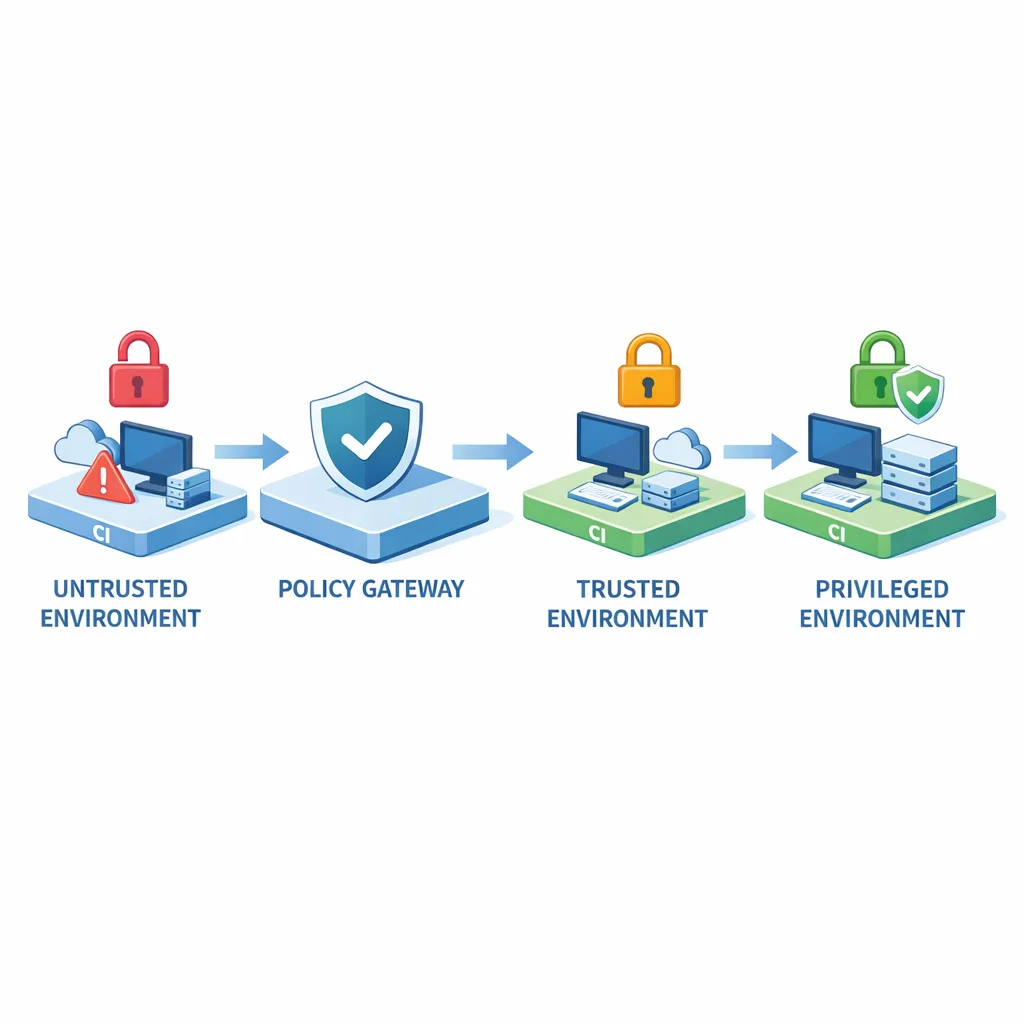
- Environment segmentation. Three lanes: untrusted (forks, research), trusted (internal repos), privileged (release, deploy). Secrets only exist in the last lane.
- Strict GITHUB_TOKEN. Read‑only by default, no org scope, rotated per workflow. For publishing, mint time‑boxed, audience‑scoped tokens with OIDC and least privilege.
- Install‑script allow‑list. Globally disable lifecycle scripts; allow only for your own packages that require build steps. Audit that list quarterly.
- Cache discipline. Content‑addressable caches per repo and branch; TTL measured in hours; never shared across trust zones. No restore from PR workflows into release workflows.
- Provenance verification. Verify SLSA/Sigstore attestations for critical dependencies; for your own packages, publish signed provenance and enforce verification in consumers.
- EDR + network egress rules in CI. Monitor and restrict where runners can talk during installs. Dependency fetching should hit only registries and mirrors.
- Secret hygiene. Rotate on a schedule, scope narrowly, prefer role assumption, and block long‑lived keys entirely where possible.
- Dependency SBOM + drift alerts. Generate SBOMs on every build; alert when “fresh” packages bypass the minimum‑age gate or when a dependency’s behavior profile changes.
Owner’s corner: what the board wants to know this week
Boards will ask three things: Were we affected? What did we rotate? What’s changing so this doesn’t happen again? Have crisp answers. If your apps touch regulated data or high‑risk AI workloads, align these controls with your governance program. If you’re shipping AI features in the EU, map software supply‑chain controls to technical documentation you’ll need anyway. Our EU AI Act 2026 compliance playbook explains how to turn engineering practices into evidence regulators recognize.
A realistic remediation timeline
Day 0–1: freeze builds, revoke tokens, quarantine hosts. Day 2–3: rebuild runners, restore services with rotated credentials, stand up an internal registry proxy with a 48‑hour minimum age. Week 2: enforce install‑script allow‑lists, provenance verification for critical packages, and network egress controls in CI. Week 3–4: SBOMs on every build, drift alerts, quarterly review ritual. This is achievable for small teams; it just needs executive cover and a crisp owner.
Gotchas we see in real teams
“We use ephemeral runners, so we’re fine.” If your ephemeral runner can assume long‑lived cloud roles or inherits write tokens for your repos, it’s not fine. Lock scopes, shorten lifetimes, and restrict egress.
“Our maintainers sign releases, so we’re safe.” Signature ≠ safety if the pipeline that builds the signed artifact is poisoned. You need both: a trustworthy build environment and verifiable provenance for the resulting artifact.
“We have MFA; attackers can’t publish.” Attackers don’t need to log in if they can trick your pipeline into doing it for them. Protect actions that mint tokens or publish artifacts as if they were production deployments—because they are.
Where Bybowu helps
If you need a partner to harden CI/CD and dependency flows without slowing delivery, our team has shipped secure pipelines for startups and enterprises. See how we instrument delivery in our write‑up, Our Web Development Process: From Discovery to Launch, and how we approach dependable upgrades in Runtime Upgrade Strategy That Ships in 2026. Or review what we build and secure on the Bybowu services page.
What to do next (this week)
- Identify any machines that installed affected packages on May 11–12, 2026. Quarantine and rebuild if in doubt.
- Rotate GitHub, npm, cloud, and SSH credentials reachable from those hosts.
- Enforce a 48‑hour minimum package age via an internal mirror, and disable install scripts in CI by default.
- Segment CI into untrusted/trusted/privileged lanes; remove cross‑lane caches and secrets.
- Enable provenance verification for critical dependencies; sign and attest your own packages.
- Ship SBOMs on every build and centralize dependency‑install telemetry.
- Run a 60‑minute tabletop using this incident. Assign owners and deadlines for the gaps you find.
Here’s the thing: the npm supply chain attack we just watched unfold isn’t an outlier—it’s the cost of running modern toolchains at scale without strong guardrails. The fixes above are boring by design; that’s why they work. Put them in place, and the next wave will be a maintenance window, not a headline.







Comments
Be the first to comment.