
Kubernetes 1.36: The Pragmatic Upgrade Playbook
Kubernetes 1.36 arrived on April 22, 2026, with 1.36.1 following on May 12. This release is a tidy mix of security hardening, storage maturity, and scheduling groundwork. The headline: platform teams finally get fine‑grained kubelet API authorization as a stable, defaultable option, while VolumeGroupSnapshot reaches GA for crash‑consistent multi‑PVC backups. If you own a production cluster, this guide distills the changes that matter, the landmines to defuse, and a battle‑tested upgrade path to adopt Kubernetes 1.36 without surprising your developers—or your pager.
What’s new in Kubernetes 1.36 that actually matters
There are plenty of line items in the release notes, but these are the ones you’ll feel in day‑to‑day operations.
GA: Fine‑grained kubelet API authorization
Historically, many shops granted broad nodes/proxy permissions so observability tools could scrape kubelet endpoints. With Kubernetes 1.36, the fine‑grained kubelet API authorization model reaches GA, letting you scope access precisely to the paths a given agent needs. The win is twofold: you can remove risky cluster‑wide privileges, and you get cleaner audit trails that map intent to permission. Translate that into action: refactor your RBAC and cut any lingering blanket nodes/proxy grants, especially in multi‑tenant clusters.
GA: VolumeGroupSnapshot for crash‑consistent backups
VolumeGroupSnapshot is now production‑ready. It lets you snapshot multiple PersistentVolumeClaims as a consistent set, which matters for stateful apps that span data and WAL volumes (think Postgres or distributed queues). If your backup runbooks pivot between per‑PVC snapshots and application‑level quiesce hooks, this GA feature reduces complexity and lets storage teams align policies across data sets.
Stable: Mutable volume attach limits
CSI drivers can now dynamically adjust node volume limits that the scheduler respects—without restarts. That minimizes false‑negative scheduling failures when a node’s effective storage capacity changes under load or error. If your on‑call rotation has been woken by pods pending due to “volume limit exceeded” even when the node was fine, this is for you.
Stable: External ServiceAccount token signer
Issuing projected service account tokens via an external signer is no longer a science project. For enterprises centralizing identity and JWT issuance, this stabilizes the integration path and simplifies long‑lived token scenarios without bespoke sidecars.
Beta: Resource health status
Clusters can surface allocated resource health inside Pod status, improving debuggability for GPUs and other accelerators. Instead of guess‑and‑check when a device plugin flakes out, controllers and operators can inspect a unified status signal and take action—like automated drain or reschedule.
Alpha: Workload Aware Scheduling (WAS)
WAS treats related pods as a single schedulable group using a PodGroup API and a revised Workload API. Translation: better placement for distributed and AI/ML jobs where “all‑or‑none” matters. It’s alpha—keep it in staging—but platform teams building internal batch/ML platforms should start evaluation now to influence roadmap choices.
Security & hygiene: gogoprotobuf removal
Removing the unmaintained gogoprotobuf dependency reduces attack surface and long‑term tech debt. You shouldn’t need to change anything, but it’s yet another nudge to review any out‑of‑tree controllers that might have quietly relied on old Proto pipelines.
Deprecations and removals you can’t ignore
Two items need explicit action:
service.spec.externalIPsis deprecated and emits warnings starting in 1.36, with removal planned in a future major cycle. If you still expose services via external IPs directly, move to LoadBalancer, NodePort for simple cases, or the Gateway API for production‑grade ingress.gitRepovolume is removed and can’t be re‑enabled. If you still had a dusty YAML using it, switch to initContainers or agit-syncstyle sidecar.
Should you upgrade to Kubernetes 1.36 now?
Short answer: yes—after a week of staging soak. The feature mix is conservative, security‑forward, and the first patch (1.36.1 on May 12, 2026) is out. Most clusters should move within the month to pick up the kubelet auth GA and storage fixes. If you’re on 1.34 or older, you’re likely approaching the end of the community support window; don’t wait for your distro to force your hand.
Kubernetes 1.36 in numbers (for managers and roadmaps)
The release delivers 70 enhancements: 18 graduated to Stable, 25 entered Beta, and 25 landed in Alpha. The release cycle started January 12, 2026 and shipped April 22, 2026; 1.36.1 patched issues on May 12, 2026. Kubernetes generally maintains roughly a one‑year support window for each minor release (plus a short maintenance tail). Vendors can be stricter; align your plan with your managed provider’s timeline.
The Kubernetes 1.36 upgrade checklist
Print this for your war room. I’ve run this play across self‑managed clusters and the big three managed services; it’s intentionally conservative.
- Inventory and risk map
- Query manifests and Helm charts for
externalIPs:andgitRepousage. Kill both before you touch control planes. - List agents scraping kubelet endpoints. Plan RBAC changes to remove broad
nodes/proxypermissions in favor of fine‑grained rules. - Identify stateful sets with multiple PVCs that could benefit from VolumeGroupSnapshot. Draft a backup validation run.
- Query manifests and Helm charts for
- Build a staging cluster on 1.36.1
- Mirror production workload patterns, secrets providers, CNI, and CSI.
- Enable beta features you plan to evaluate (for example, resource health status) in staging only.
- Revise RBAC for kubelet API authorization
- Replace blanket permissions for monitoring agents with path‑scoped rules that match their scrape endpoints.
- Update runbooks: where to look if a scrape fails (RBAC deny vs endpoint unreachable).
- Modernize backups with VolumeGroupSnapshot
- Create snapshot classes and policies for grouped volumes.
- Run a restore dry‑run into a staging namespace; validate application‑level consistency.
- Storage scheduler hygiene
- Ensure your CSI drivers support mutable attach limits; update sidecars if your vendor recommends it.
- Audit pending pods caused by outdated limits; confirm reductions once mutable limits are active.
- Admission & identity
- If you’re centralizing JWT issuance, flip to the external ServiceAccount token signer in pre‑prod and verify token lifetimes, audience, and rotation.
- Document fallbacks if the external signer is unreachable.
- Canary the control plane
- Upgrade one region/cluster first. Hold for 48–72 hours to watch etcd, API latency, and admission controller performance.
- Ensure the kubelet skew is respected: worker nodes should not lag more than one minor behind the API server.
- Roll workers by pool
- Use surge and disruption budgets tuned to your SLOs (e.g., PDBs at 60–70% availability, HPA minReplicas increased temporarily).
- For GPU pools, validate the device plugin against the resource health status signals.
- Post‑upgrade hardening
- Remove any temporary RBAC exceptions created for the cutover.
- Turn on warnings as errors in CI for deprecated fields like
externalIPs.
What might break—and how to preempt it
Most 1.36 issues I’ve seen fall into three buckets. Here’s how to check each quickly.
1) Deprecated networking shortcuts
Symptom: Someone used externalIPs for a “temporary” exposure that stuck around. Warnings pop up; future removal will be painful if ignored.
Fix: Migrate to LoadBalancer or Gateway API. If you truly need node‑local debugging, wrap it in a break‑glass runbook with time‑boxed exceptions.
2) Legacy volume patterns
Symptom: Workloads still referencing the removed gitRepo volume type fail to mount on 1.36.
Fix: Replace with initContainers that git clone into an emptyDir, or adopt a git-sync sidecar. While you’re there, audit for writable image anti‑patterns.
3) Over‑permissive monitoring
Symptom: After tightening kubelet auth, dashboards go red because scrapers expected nodes/proxy superpowers.
Fix: Create role templates per agent (Prometheus, Datadog, etc.). Scope access to the exact kubelet routes each tool requires and bake those templates into your Helm values.
People also ask
Does Kubernetes 1.36 change default cluster security?
It doesn’t flip a magic “secure by default” switch, but it makes the secure path first‑class. With kubelet auth GA, you can finally remove fragile workarounds and enforce least‑privilege without custom patches. Combine this with sane admission policies and you meaningfully lower blast radius for compromised agents.
How long will 1.36 be supported?
Plan for roughly a year of community support from release, plus a short maintenance tail; your managed provider’s policy may be tighter. That gives you a comfortable window to adopt 1.36 in Q2–Q3 2026 and still have time for a later‑year patch bump.
How does Kubernetes 1.36 help AI/ML workloads?
Two ways. First, resource health status brings better signals for accelerators, reducing black‑box failures. Second, Workload Aware Scheduling (alpha) is the clearest step yet toward native gang‑style placement for distributed training jobs. Don’t use it in production yet, but start testing if your platform supports batch or ML teams.
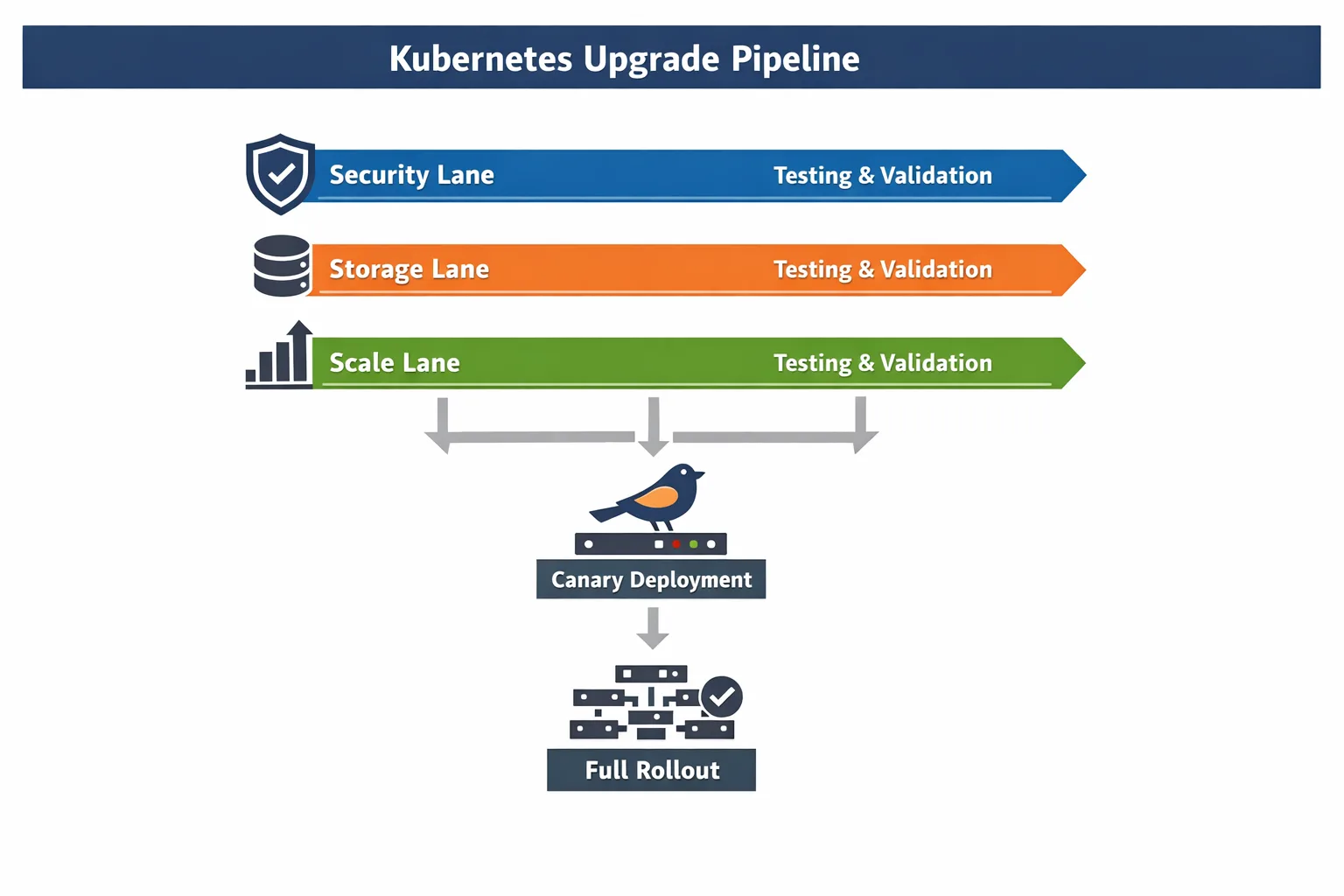
A simple framework for your 1.36 rollout
I use a three‑lane model to keep everyone aligned:
- Lane A: Safety — RBAC refactor for kubelet auth, externalIPs removal, admission policy checks. Owner: Security/Platform.
- Lane B: State — VolumeGroupSnapshot enablement and restore validation, CSI sidecar updates, dynamic attach limits. Owner: Storage/SRE.
- Lane C: Scale — Staging experiments: resource health status integration and early WAS trials. Owner: Platform R&D.
Each lane has a “definition of done” and a rollback plan. Tie them together with a single change calendar and a runbook that names who’s paged for what.
Hands‑on snippets you can reuse
Quick checks that save hours:
- Find deprecated fields in manifests
grep -R "externalIPs\s*:" ./manifests ./charts - Hunt for removed volume types
grep -R "gitRepo\s*:" ./manifests ./charts - Spot agents hitting kubelets
kubectl -n monitoring get pods -o yaml | grep -E "kubelet|10250|10255" - Validate grouped snapshots policy objects exist
kubectl get volumegroupsnapshotclass
Team and stakeholder alignment
Upgrades fail when responsibilities blur. Publish a short memo: what changes in Kubernetes 1.36, how it improves security, who owns each lane, and how you’ll measure success (SLO error budgets, upgrade duration, and post‑upgrade incident count). Put dates on the calendar now: staging cutover within a week, first production canary the week after, and full rollout by end of month if signals stay green.
Where this fits in your broader platform roadmap
1.36 is a good moment to re‑baseline cluster governance. If you’re on AWS, use this window to tighten IAM guardrails around EKS so kubelet scope downsizing doesn’t collide with lax cloud permissions. If you’re consolidating tooling or re‑platforming services, our cloud modernization services team can map 1.36 features to tangible SLO and cost outcomes. And if you want more technical playbooks like this, browse the latest on our engineering blog.

Risks, limits, and edge cases to respect
Alpha features remain alpha. Keep Workload Aware Scheduling and any feature‑gated experiments in staging. Don’t assume every CSI driver immediately supports dynamic attach limits—verify with your vendor. And remember that managed services stagger rollouts; a “v1.36” label doesn’t guarantee identical sidecar or kernel versions across providers.
What to do next (this week)
- Stand up a staging cluster on Kubernetes 1.36.1; mirror production add‑ons.
- Run the manifest audit for
externalIPsandgitRepo; file tickets to remove them. - Refactor RBAC for kubelet scraping agents; test dashboards under least‑privilege.
- Enable VolumeGroupSnapshot in pre‑prod and complete a restore rehearsal.
- Book your canary: pick one low‑risk cluster, upgrade control plane, soak 48–72 hours, then roll workers.
If you want a second set of eyes on your plan—or you’d like us to run the playbook end‑to‑end—talk to us. We’ve helped teams ship upgrades like this across regulated industries, high‑throughput SaaS, and GPU‑dense research clusters. The upside is real: fewer late‑night incidents, faster restores, and guardrails your auditors will actually like.






Comments
Be the first to comment.