
California Delete Act: 2026 Engineering Playbook
The California Delete Act is no longer a headline—it’s an engineering project with concrete dates, fees, and penalties. In January 2026, the state launched the Delete Request and Opt-out Platform (DROP), a one-stop portal where Californians can send a single deletion request to every registered data broker. Starting August 1, 2026, brokers must log in at least every 45 days, retrieve requests, and report status within 45 days. If you’re a data broker—or your product buys from or sells to one—this is the moment to translate policy into code.

What shipped in January 2026—and why it matters
DROP is a state-run website designed to scale consumer deletion requests across hundreds of data brokers. Consumers submit one verifiable request; brokers must delete matching personal information they hold—often including inferences—unless a legal exception applies. The platform also creates a standardized status and reporting loop that the California Privacy Protection Agency (CPPA) can audit.
Engineers should treat DROP as a new system-of-record input. It will generate recurring, legally binding instructions that your services need to ingest, match, act upon, and remember indefinitely so data doesn’t reappear through re-ingestion or enrichment. The operational model is closer to a suppression registry than a one-time purge.
Key dates and obligations
Here’s the short, actionable timeline teams are aligning to in 2026:
- January 1, 2026: DROP opens to consumers; data brokers begin 2026 registration via the CPPA (fee: $6,000 plus payment processing).
- January 31 (annual): Data brokers must be registered or face fines for each day unregistered.
- August 1, 2026: Brokers must access DROP at least every 45 days to retrieve requests and process them; brokers must report request status within 45 days of retrieval.
- July 1 (following the first qualifying year): Publish request metrics in your privacy policy and include a link; be prepared to provide prior-year metrics to CPPA during registration.
- January 1, 2028 and every 3 years after: Independent compliance audits required for data brokers.
Penalties are real: administrative fines can accrue per day of non-registration and per deletion request per day if you fail to delete as required. Build for continuous compliance, not one-off tasks.
“Are we a data broker?” A practical test
Legally, a data broker is a business that knowingly collects and sells personal information about consumers with whom it doesn’t have a direct relationship, subject to exceptions. But labels are messy in practice. Use this quick test to triage with your counsel:
- Do you acquire personal data from third parties or public sources and then sell or share it with customers who don’t have a direct relationship with those consumers?
- Do you enrich client data with third-party attributes and resell the enriched profiles?
- Do you sell or share identifiers like mobile advertising IDs, connected TV IDs, or hashed emails tied to audiences?
- Do you operate people-search, lead-gen, list rental, risk scoring, identity resolution, or location data services?
- Do you monetize inferred attributes (propensity, interest, household composition) at scale?
If you answered yes to one or more, you likely need a broker-readiness plan. If you partner with brokers (as a brand or app developer), you still need to honor delete signals in downstream systems and contracts.
California Delete Act obligations, translated for engineers
Let’s convert the law into systems behavior your team can ship in Q1–Q3 2026.
1) Create a canonical identity map
You can’t delete what you can’t reliably match. Build or harden an identity service that maps common broker keys: name, email(s), phone(s), mailing address, IP ranges, device IDs (IDFA/GAID/MAID), CTV IDs, vehicle identification numbers, and customer IDs. Store historical aliases and prior identifiers for durable matching. Log confidence scores for each linkage.
2) Ingest DROP request payloads on a fixed cadence
Plan to poll DROP at least every 45 days; most teams will set a weekly or biweekly pull to reduce backlog risk. Normalize incoming requests into a standard internal schema and assign a unique internal deletion ticket with timestamps for retrieval and processing windows.
3) Build a two-step action: purge and suppress
Deletion is not enough if your pipelines can re-import a consumer from partners tomorrow. After purging matched records across systems, write a suppression token to a durable registry so future ingests can detect and refuse re-collection for that identity, unless a legal exemption applies. Treat this like an “eternal unsubscribe.”
4) Propagate deletes across the full data graph
Enumerate where the data can live: OLTP stores, data lakes/warehouses, streaming topics, caches, search indexes, analytics stores, feature stores, backups, long-term archives, and vendor APIs. For each, define the deletion method, latency target, and verification. For backups you can implement delete-at-restore policies plus strict read-blocking through suppression lists.
5) Handle inferences explicitly
The Delete Act extends to inferences derived from personal data. That means your models’ feature stores and labels may contain attributes you must purge. Record the lineage from source identifiers to derived features so your delete job can traverse and clean predictions, segments, and lookalikes tied to the person.
6) Return status within the 45-day window
Status must reflect whether you deleted, denied under a legal exemption, or processed an opt-out of sale/sharing when deletion can’t be honored. Implement a clear state machine and persist evidence (logs, hashes of deleted records, job IDs) for audits.
7) Guard against reinsertion
Enforce suppression checks at every ingress: batch imports, partner feeds, SDK events, acquisition uploads, and manual CRM enrichments. Add CI tests that seed “deleted” identities through staging pipelines to confirm they get rejected or masked before storage.
8) Vendor orchestration
Inventory vendors that receive personal data or inferences. Amend DPAs to require timely, verifiable deletes and to honor your suppression tokens. For vendors who also source from brokers, require they honor DROP-derived deletes regardless of the original source.
9) Metrics and public disclosures
Prepare to report counts for deletion, access/know, sale/share opt-out, and sensitive data limitation requests, plus the mean/median time to respond. Instrument your workflow now so you can generate these metrics without a spreadsheet fire drill at registration time.
10) Audit readiness from day one
By 2028 you’ll face a third-party audit. Keep immutable logs (e.g., append-only store) of request intake, matching decisions, propagation steps, and final states. Retain architecture diagrams, data inventories, and SOPs that prove your process works, not just once but every cycle.
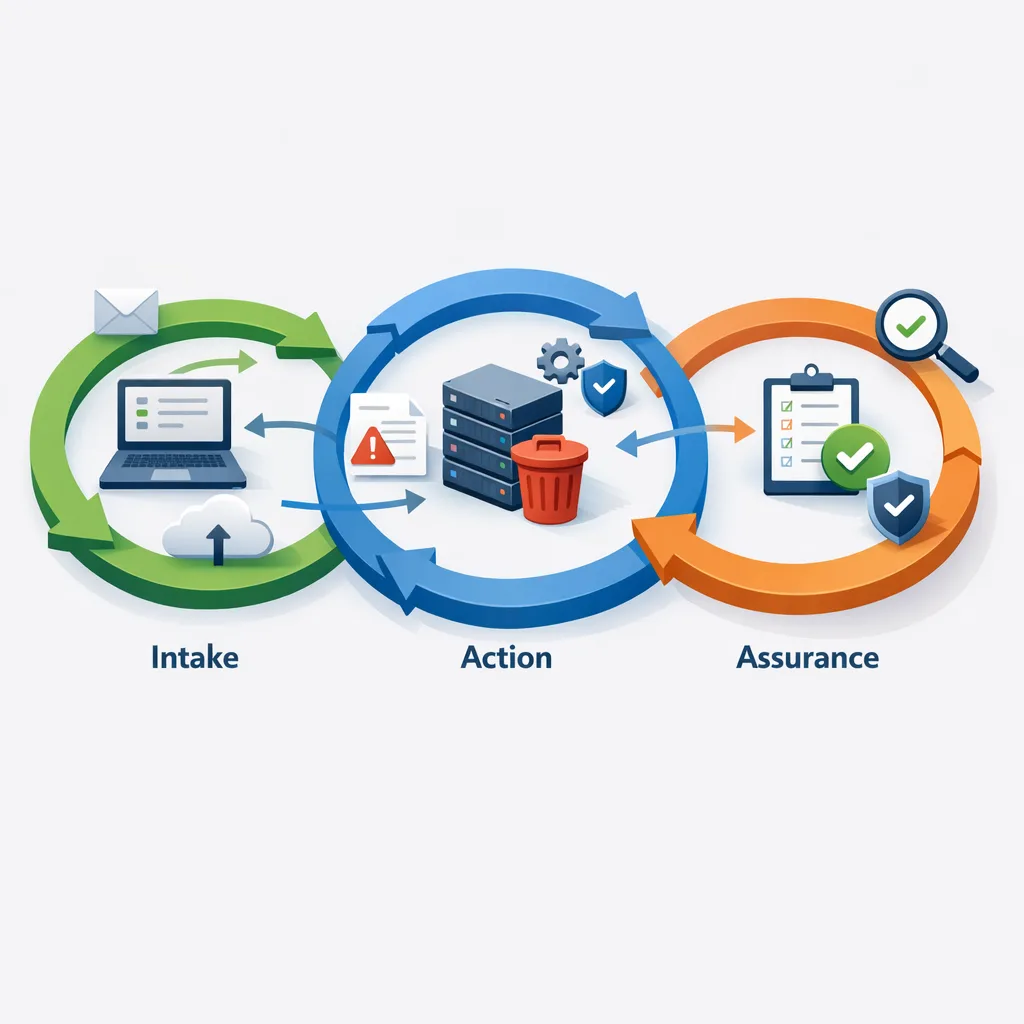
How DROP requests flow through your stack
Think in terms of three loops: intake, action, and assurance.
Intake: You retrieve requests from DROP on a scheduled job. Each request contains consumer-provided attributes for matching. You create a case record and start the clock.
Action: Your matching service links the request to identities with a confidence threshold and generates a deletion plan across systems and vendors. Purge executes, suppression tokens are written, and partner tasks are dispatched. If deletion doesn’t apply, convert the request to an opt-out of sale/sharing and update data flows accordingly.
Assurance: You verify each target system reported success, re-scan to ensure no replicas remain, and publish status back within 45 days. The case stays open with a watch period to catch late-arriving copies from slow pipelines.
Edge cases and implementation traps
Backups and archives: Most teams can’t surgically edit immutable backups. Block reads for deleted identities, document your policy, and ensure restores immediately replay suppression lists to scrub reintroduced rows.
Streaming systems: Kafka or Pub/Sub topics can retain personal data longer than you think. Apply field-level encryption or tokenization at publish time and include delete-aware compaction where possible. At minimum, prevent republish of deleted identities from dead-letter queues.
Inferences in ML: If a consumer’s records trained a model, you don’t have to retrain the model retroactively unless a specific law or commitment says otherwise. But if you store per-user features, labels, or personalized embeddings, those are in scope for deletion. Log which features and segments you dropped.
Re-collection risk: Your lead-gen partners might send you the same person after you’ve processed a delete. Your suppression registry must run before any storage. That means rejecting or salting identifiers at the edge (SDK, API gateway, ETL) before they touch core stores.
Household and joint accounts: If your data includes inferred household links, be careful to sever only the deleted individual’s ties while preserving other household members. Document the logic and make it testable.
International flows: If you replicate to EU or APAC regions for latency, your delete job must cross regions. Keep a single controller that tracks completion status per region and vendor.
Does the Delete Act apply if we don’t “sell” data?
Many teams assume “we don’t sell” ends the conversation. Not necessarily. If you share personal information for cross-context behavioral advertising or audience building, you may still trigger obligations. The safest engineering posture is to honor deletion and opt-out signals consistently, then rely on counsel to apply exemptions where appropriate.
What if we’re a brand, not a broker?
You still need to honor deletes from your own users and ensure your contracts require partners (including brokers and enrichment vendors) to pass your deletes downstream and to respect DROP-derived deletions they receive. Add a routine to map DROP identities you receive from vendors to your CRM so you don’t re-import them during future campaigns.
California Delete Act vs CCPA: what’s different now?
CCPA gave consumers rights and businesses processes. The California Delete Act adds scale and enforcement specifically for data brokers, including a common intake (DROP), recurring retrieval obligations, expanded disclosures, and periodic audits. For engineering teams, the biggest difference is the durable suppression layer to prevent re-collection from the broader data economy.
How to size the work (and ship without drama)
For a typical mid-size data broker with five core systems, three analytics stores, and a handful of adtech partners, plan for a 6–10 week push:
- Week 1–2: Data inventory, identity map hardening, and DROP intake scaffolding.
- Week 3–5: Delete orchestration across systems, suppression registry, and partner webhooks or ticketing.
- Week 6–7: Metrics and reporting automation, privacy policy updates, and DPA amendments.
- Week 8–10: Disaster tests, audit trail review, load testing on bulk requests, and runbooks.
If you need a partner to accelerate, our team specializes in privacy engineering and audits and has shipped similar frameworks alongside broader security programs. See how we operate on what we do and browse more shipping playbooks on our blog.
A broker-readiness checklist you can adopt today
Print this, put owners next to each line, and track to green:
- Owner named for DROP intake and status reporting.
- Identity resolution service supports all common broker identifiers and alias history.
- Suppression registry implemented and enforced at every ingest path.
- System-by-system delete methods documented with latency targets.
- Inference deletion path defined for segments, features, and lookalikes.
- Vendor matrix with delete SLAs and verification proof.
- Metrics dashboard for counts and response times, exportable for registration.
- Immutable audit logs and quarterly spot checks.
- Backup restore policy that re-applies suppression on load.
- Load test for a large DROP batch; defined on-call and rollback plan.
People also ask
Can we deny a request and just opt the person out?
Sometimes. If a lawful exception applies (for example, a regulatory requirement to retain certain records), you must still process the request as an opt-out of sale/sharing when deletion can’t be honored. That opt-out must propagate across your systems and partners.
How do we prove deletion without retaining personal data?
Store non-reversible evidence: job IDs, timestamps, counts by system, and salted or hashed identifiers that can’t be reconstructed. Keep a separate suppression token that blocks re-ingest without exposing the original identifier.
Does the Delete Act apply to B2B contact data?
Yes—personal information includes data about people in a business context. If you broker or enrich B2B contacts, treat them as in scope unless an explicit exemption applies.
What about mobile apps and MAIDs?
If your product sells or shares device-based identifiers or segments derived from them without a direct relationship with the consumer, you may fit the broker definition. Your deletion flow must purge and suppress those IDs and any segments created from them.
Zooming out: product and growth implications
Good deletion engineering doesn’t fight growth—it protects it. Teams that implement suppression-first architectures discover they ship faster later. Your data model becomes safer to enrich, your vendors easier to manage, and your audits easier to pass. Marketing can still run, with fewer compliance landmines.
Expect the ecosystem to align to DROP signals. Brokers will expose APIs and dashboards to confirm status; brands will want automated attestations from vendors. Build with that future state in mind: standardized events, machine-verifiable proofs, and a single service that speaks for your company when a delete shows up.

What to do next
Let’s get practical:
- This week: Name an owner, draft your system inventory, and schedule the FIRST retrieval job. Don’t wait for August—simulate requests now.
- Next two weeks: Implement suppression at ingest, wire the delete orchestrator, and update vendor DPAs with enforcement language.
- By end of month: Stand up metrics and publish the public-facing privacy page with request metrics link. Run a red-team drill: attempt to re-ingest a deleted identity.
- Quarterly: Audit a random sample of closed cases, verify suppression is still working, and review partner attestations.
If you want a seasoned team to co-own the hard parts, we offer fixed-scope privacy sprints and ongoing advisory—start with our pricing overview and talk to us.
The Delete Act is engineering work, not just a compliance checkbox. Ship the plumbing now so August 2026 feels like a routine cron job, not a fire drill.




Comments
Be the first to comment.