
GitHub Actions Self‑Hosted Runners: March 2026 Guide
GitHub Actions self‑hosted runners are getting enforcement changes in March 2026 that will break neglected fleets. There’s also a pricing storyline that was announced for March 1 and then postponed, which means you should plan for cost exposure even if it’s not charging today. If your production releases depend on GitHub Actions self‑hosted runners, treat this week like a change window, not a watch party.

What’s changing in March 2026 for GitHub Actions self‑hosted runners
Two threads matter. First, GitHub will enforce a minimum version for the self‑hosted runner application. Starting mid‑March, new configurations from runners older than the required version will be blocked. Brownout windows in late February and early March already previewed the failure mode. If your fleet is on an old binary, registration and configuration can fail even before you run a job.
Second, the pricing picture: GitHub introduced a platform charge of $0.002 per minute as part of a broader Actions pricing update and initially targeted self‑hosted enforcement for March 1, 2026—then postponed that portion to re‑evaluate. Hosted runners already saw up to a 39% price reduction on January 1, 2026, but self‑hosted teams should still model what happens if that $0.002/minute charge lands later this year.
The minimum runner version—and why it’s a hard gate
GitHub’s minimum runner version requirement isn’t hand‑waving. It’s a configuration‑time gate: runners older than the specified version (v2.329.0 or newer is the common marker) can’t register. Older nodes don’t just “run slower”—they fail to join the party. If you use ephemeral runners created on demand, image baking with an outdated runner binary will silently produce broken capacity.
Here’s the thing: some teams rely on runners “self‑upgrading” during provisioning. Don’t. The new gate can block before self‑upgrade kicks off. Bake a compliant runner version into images and AMIs, confirm the checksum, and require the version in your orchestration.
Pricing outlook for self‑hosted: postponed, not canceled
GitHub communicated a $0.002 per‑minute Actions platform charge for self‑hosted runners, then postponed enforcement to gather feedback. Practically, finance may’ve paused, but engineering shouldn’t. If your org runs 50,000–200,000 minutes per month on self‑hosted, a charge at that level translates to $100–$400 monthly—small for many enterprises, but real money at scale. If you’re burning millions of minutes across monorepo builds and heavy integration tests, it can jump to thousands per month. Assume it returns later in 2026 and get ahead with optimizations you should do anyway: cache smarter, parallelize narrower, and cut dead minutes.
Why this matters: risk, reliability, and runway
Self‑hosted is attractive for control, speed, and cost—but only if you keep the control plane happy. The mid‑March gate is a reliability risk: treat it like a dependency update with an external deadline. Meanwhile, the pricing storyline changes your unit economics. If you can move 20–40% of your minute burn off self‑hosted jobs that don’t uniquely need your hardware, you hedge both policy and price. Also consider runtime deprecations that collide with your CI images—Node.js 20, for example, reaches end‑of‑life on April 30, 2026, and that’s going to ripple through build containers and tests.
Zooming out, this is also your chance to kill brittle snowflake runners, unify labels, and make ephemeral the default. The longer you wait, the more “upgrades” turn into late‑night firefights.
Your 72‑hour upgrade and audit playbook
Use this as a strict, time‑boxed plan. It fits a weekday sprint and avoids multiweek rabbits.
Hour 0–8: Inventory and blast radius
• List all autoscaling groups, AMIs, VM templates, or container images that install or bake the Actions runner. Capture the runner version in each. Map labels to repositories and critical workflows.
• Grep your org for runs-on: [self-hosted, ...] usage, then extract labels. Assemble a dependency tree: which repos trigger which labels?
• Flag ephemeral versus long‑lived nodes. Ephemeral should be your north star, but long‑lived exists—note them.
Hour 9–20: Make it build‑proof
• Upgrade the runner binary in all images to the required version or newer. Pin by SHA or an internal artifact, not a floating tag.
• Add a pre‑flight job in a throwaway workflow that asserts runner version and fails fast with a helpful message.
• If you use Actions Runner Controller (ARC) or a scale‑set client, update Helm charts and controller images, and roll a small canary set first.
• For long‑lived nodes, run an in‑place upgrade with maintenance windows and a rollback switch.
Hour 21–36: Prove you can fail safely
• Induce a brownout locally by pointing a staging org to a blocked version (or simply disable runner registration) and confirm your alerting fires before a release train is impacted.
• Validate that autoscalers replace drained nodes quickly and that image pulls aren’t a hidden bottleneck.
• Bake the runner version and an OS patch baseline together. Don’t ship a new runner on a stale kernel.
Hour 37–56: Cut dead minutes
• Cache: Move heavy language caches (Node, Java, Python) to a shared, region‑local cache with content addressing. Cap TTLs so you don’t ship stale base layers.
• Parallelize smaller: Stop over‑sharding—prefer fewer, fuller jobs over many tiny ones that spend half their time in checkout and setup.
• Test selection: Adopt change‑based test runners or split slow E2E suites into smoke vs. nightly. That alone can cut 30–50% minutes.
Hour 57–72: Lock down and document
• Network: Restrict egress to artifact stores, registries, and your VPC endpoints only. No open internet from runners.
• Secrets: Move deploy keys to OIDC with short‑lived tokens; eliminate long‑lived PATs on disk.
• Runbooks: Document labels, versions, AMIs, upgrade steps, and an emergency runner bypass. Architecture lives in wikis or it doesn’t exist.
People also ask: quick answers
Will older runners auto‑upgrade and dodge the gate?
Don’t count on it. The enforcement happens at configuration time. If your runner needs to register—and many ephemeral designs do—it can be blocked before any self‑update script runs. Bake the correct version into images.
Does this affect GitHub Enterprise Server?
Enterprise Server has its own cadence and compatibility matrix. But if you point Enterprise Server at the Actions service or use the same runner binaries, you still inherit runner version requirements. Keep versions aligned.
How do I see which workflows hit self‑hosted runners?
Search your org for runs-on: self-hosted and any custom labels. Build a simple usage report from job logs to tally minutes per label, then prioritize the top three labels for optimization. If your org streams Actions logs to observability, tag by label and repo to track minute burn weekly.
Cost modeling if the self‑hosted platform fee returns
Even though the self‑hosted platform charge is postponed, you should model scenarios. The math is simple and keeps you honest with stakeholders.
• Baseline: Minutes per month on self‑hosted runners (M).
• Hypothetical platform rate: $0.002 per minute (R).
• Monthly charge: M × R.
Examples:
• 50,000 minutes → $100/month.
• 250,000 minutes → $500/month.
• 2,000,000 minutes → $4,000/month.
Where to save minutes fast:
• Trim checkout and setup: move monorepo bootstraps to prebuilt cache layers.
• Right‑size concurrency: avoid idle parallelism that hoards executors.
• Artifact hygiene: don’t upload giant artifacts on every PR—gate them on labels or branches.
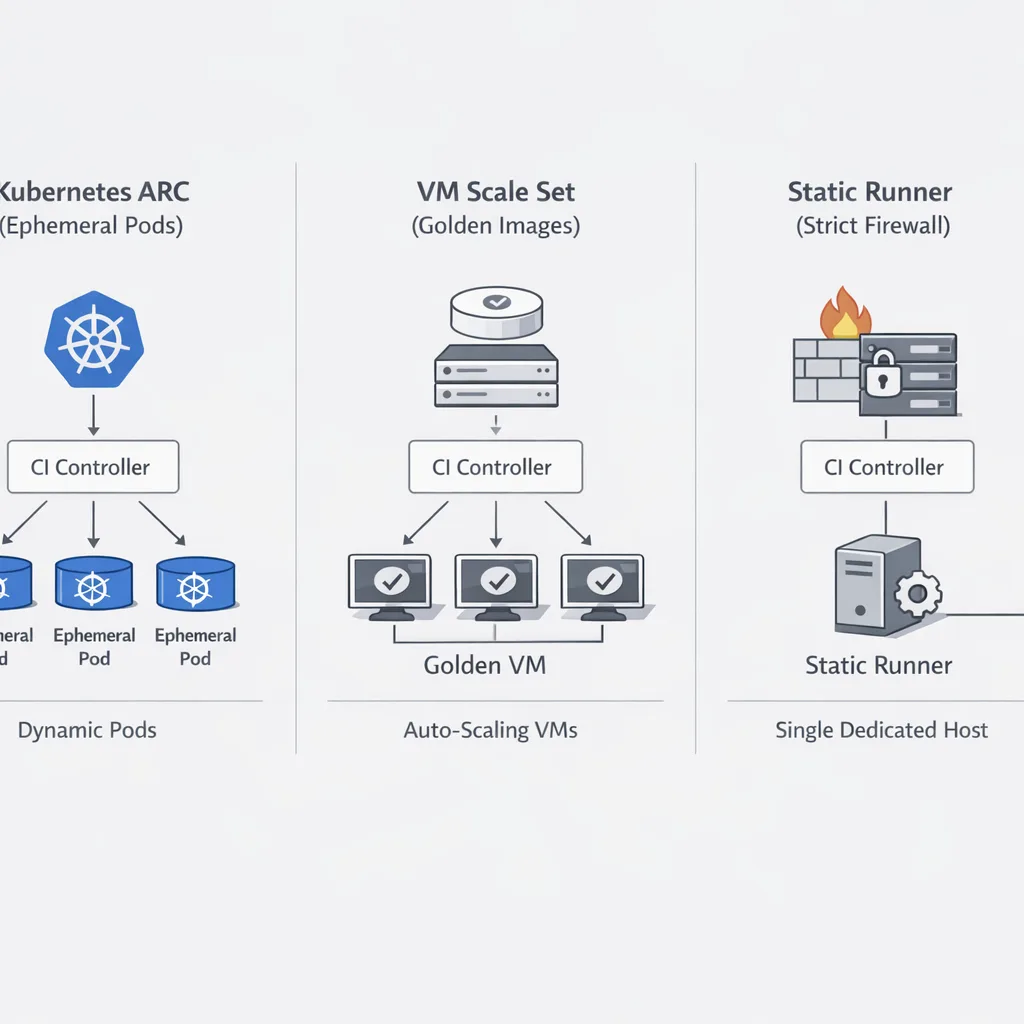
Architecture options in 2026: what to run where
There isn’t one “right” runner architecture. Pick a pattern that matches your constraints and the jobs you run most often.
ARC on Kubernetes for elastic fleets
If you already operate a stable Kubernetes stack, Actions Runner Controller (ARC) gives you autoscaling, ephemeral pods, and policy controls. Bake runner images with the right version, labels, and your network egress policy. ARC shines for bursty PR traffic and language‑diverse monorepos.
Scale‑set clients and VM pools
Some orgs prefer VM pools or a lightweight scale‑set client for Windows or macOS jobs, legacy build tools, or GPU workloads. The key is to make these nodes disposable. Golden‑image everything, tag instances with runner version, and rotate aggressively.
Static runners—only if you must
Long‑lived hosts are easy to reason about and tough to keep clean. If compliance or hardware constraints force static nodes, schedule weekly re‑imaging, disable interactive logins, and auto‑revoke credentials after each job.
Security refresh for runners: the 2026 checklist
Self‑hosted gives you control; use it. Here’s a modern hardening baseline aligned to today’s threats.
• Egress control: Permit only registries, package mirrors, artifact stores, and your SaaS endpoints. Block wildcard internet. If you’re deploying AI agents or tools in CI, pair this with an egress policy; we detailed the approach in our guide on egress firewalls for AI agents.
• Ephemeral by default: New VM/pod for every job, new identity, zero reuse of workspaces.
• OIDC everywhere: Replace stored secrets with short‑lived, auditable tokens. Scope them so a compromised job can’t laterally move.
• Action pinning: Use commit SHAs, not floating tags. Build a quarterly review to update pins.
• SBOM and attestation: Generate SBOMs in CI and sign build artifacts. Store provenance alongside artifacts.
Avoid surprise runtime breaks in your images
Don’t ship a fresh runner on a stale toolchain. Many fleets will find Node.js 20 baked into images; it reaches end‑of‑life on April 30, 2026. Use this change window to refresh base images to Node.js 22 or newer and re‑test your toolchain. If your org needs a playbook, we’ve published a fast track: Node.js 20 EOL: the 45‑day upgrade.
Operational guardrails you can add in a day
• Pre‑flight job: First step in every workflow checks runner version, OS patch level, and required network reachability. Fail fast with a human‑readable message and a link to your runbook.
• Label SLOs: Track queue time and success rate per label weekly. Labels that miss SLOs get capacity or get retired.
• Canary channel: One label (e.g., self-hosted-canary) always runs newest runner images and controller versions. High‑value repos route a subset of PRs there.
Where to move minutes off self‑hosted (when it helps)
Some jobs don’t belong on your hardware. If your hosted runner prices are lower post‑January cuts and you can finish faster on bigger ephemeral machines, move PR linting, unit tests, and light integration tests to hosted. Keep self‑hosted for secrets‑sensitive publish steps, GPU/metal needs, or private network integration. The mix should be a finance‑informed performance decision, not a dogma.
What to do next
• Today: Upgrade all images to the required runner version or newer, then add a pre‑flight version check in every workflow.
• This week: Run the 72‑hour playbook, set label SLOs, and put egress controls in place. Kill long‑lived runners unless there’s a written exception.
• This month: Model the postponed $0.002/minute fee at your actual minute burn. Cut 20–30% with caching and test selection. Decide which jobs move to hosted for speed or cost.
• This quarter: Standardize on ARC or a scale‑set client with golden images, adopt OIDC end‑to‑end, and add SBOM + provenance to your release pipeline.
If you want a deeper, org‑ready version of this plan—including Terraform snippets, Helm values, and label SLO templates—start with our focused primer: GitHub Actions self‑hosted runner March 2026 plan. If you need help implementing, see our engineering services and practical case studies in the portfolio. For broader CI/CD budgeting, our team can also map the Actions pricing model to your pipeline minutes and provide a right‑sizing report—see pricing for engagement options.

Bottom line
Don’t let a configuration‑time gate take down your release train. Update your GitHub Actions self‑hosted runners now, assume a platform fee might land later in 2026, and use the moment to eliminate dead minutes, harden security, and standardize your runner architecture. You’ll ship more predictably, spend less, and sleep better when the next brownout rolls through.








Comments
Be the first to comment.