
Node.js 20 EOL: Your 7‑Day Fix Plan
Node.js 20 EOL hit on April 30, 2026. Use this 7‑day plan to migrate to Node 22/24 fast—plus AWS Lambda and GitHub Actions deadlines.
Latest updates, insights & development notes
Discover cutting-edge strategies and innovative solutions
Node.js 20 EOL hit on April 30, 2026. Use this 7‑day plan to migrate to Node 22/24 fast—plus AWS Lambda and GitHub Actions deadlines.

What to ship now for a safe, fast move to Kubernetes 1.36: what changed, what breaks, and a hands-on checklist for platform teams.
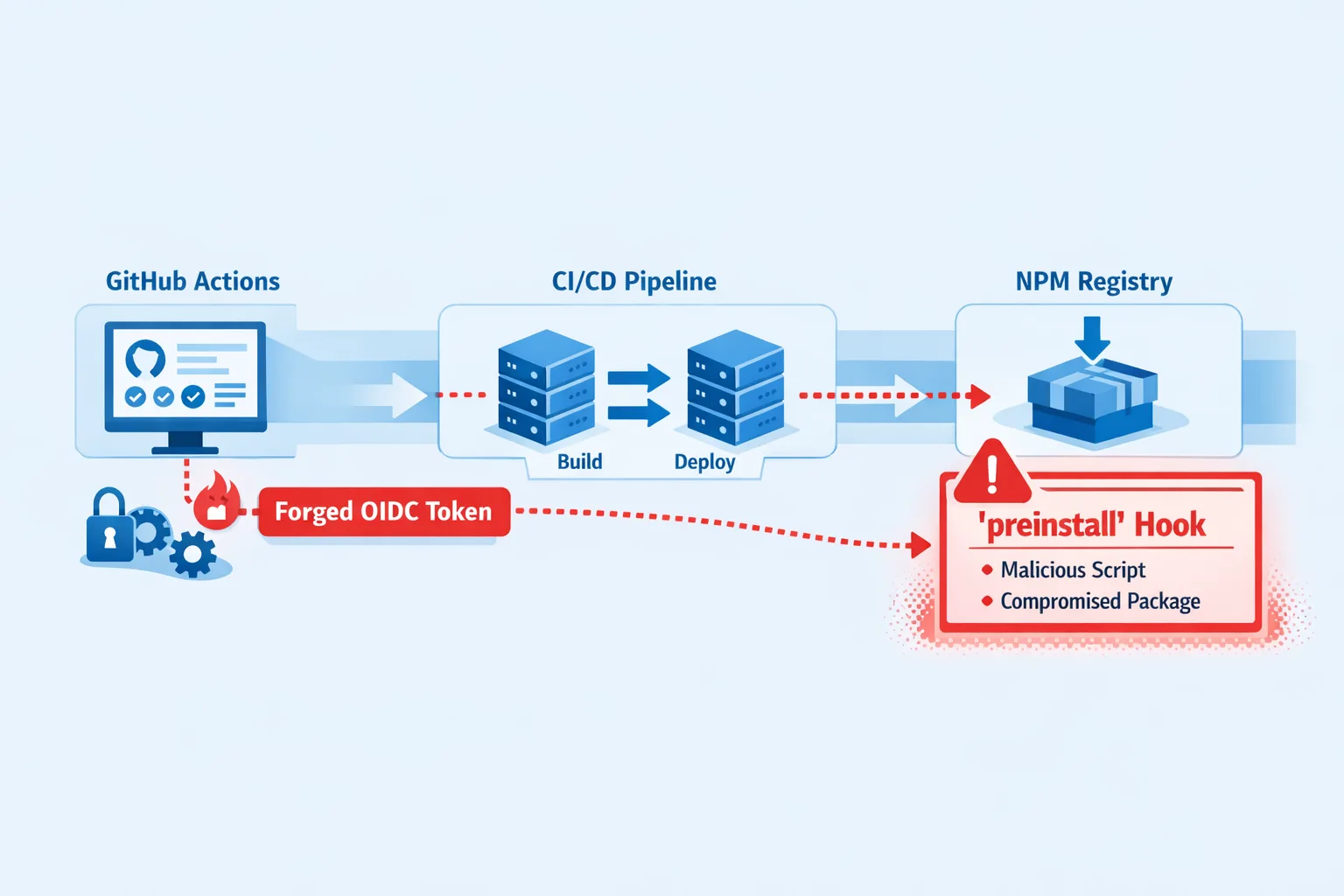
Red Hat’s @redhat-cloud-services npm packages were backdoored. Here’s what happened and how to harden OIDC trusted publishing and your CI/CD now.

Salesforce is buying Contentful. Here’s what it means, risks to plan for, and a practical 90‑day playbook for developers and execs.

What dev teams should ship for real-time video generation in 2026: stack choices, latency math, risks, and a 30‑day action plan.

Rolling out since May 21, Google’s May 2026 Core Update + new spam rules change the playbook. Here’s what shifted and the actions to take this week.
Cloudflare Workers AI deprecations land on May 30, 2026. See which models go away, safer replacements, and a 7‑day migration plan that avoids breakage and ...

Google I/O 2026 just rewired Search with AI agents and a new box. Here’s what developers and SEO teams must change now—technical, content, and analytics.

Angular 19 reached EOL on May 19, 2026. Use this practical 30‑day plan to upgrade to Angular 21 safely—versions, tooling, CI, and risk controls.
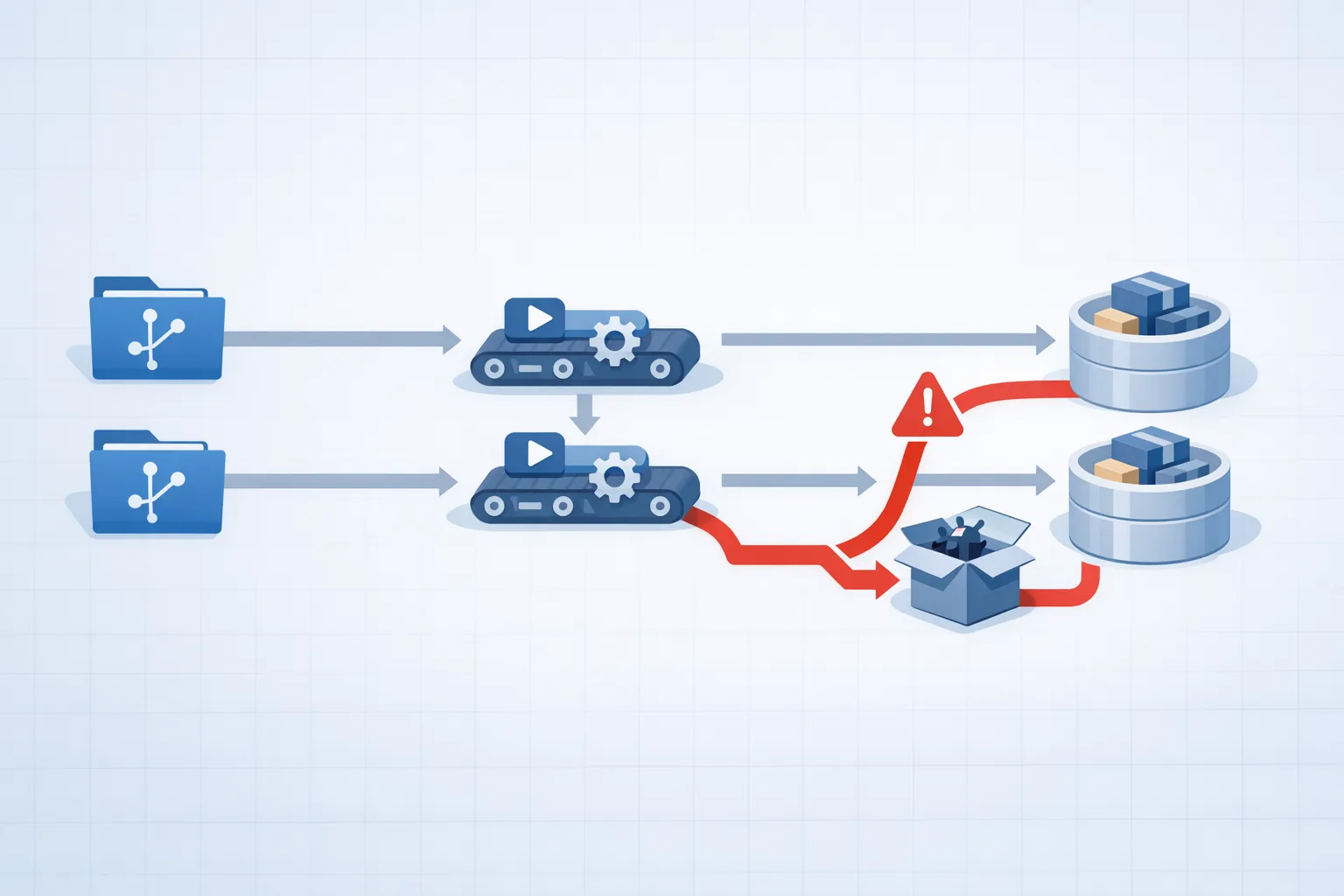
TanStack and Mistral SDKs were hit. Here’s how to triage, rotate secrets, harden CI, and prevent the next npm supply chain attack—this week.

New EKS IAM condition keys let you enforce private endpoints, KMS encryption, version policy, and deletion protection. Here’s how to roll them out.

What’s new in Next.js 16.2 and how to upgrade safely: Adapters, Turbopack, AI tools, error handling, and a step‑by‑step rollout plan.