
Here’s the headline: Cloudflare AI bot protection isn’t niche anymore. Over the past few months, Cloudflare has moved from “nice to have” toggles to a full posture for managing AI crawlers—blocklists, per-crawler controls, and even the beginnings of a paid access model. This week, Cloudflare highlighted that it has blocked an eye-popping volume of AI bot requests since July 1, 2025, signaling that automated scraping is no longer a rounding error. If you publish content or operate a product that attracts copycats, it’s time to tune your defenses without kneecapping your SEO.
What changed this week—and why it matters
Three developments converged:
First, Cloudflare said the volume of attempted AI scrapes it’s intercepting is massive. That validates what many of us see in logs: unfamiliar user agents, odd referrers, and “empty calorie” traffic hammering content endpoints. Second, Google’s Search leadership reiterated on December 4, 2025 that AI-assisted experiences will deepen, with more conversational follow-ups and richer answers while still driving outbound clicks. Translation: you can’t treat “AI” as separate from “Search” anymore; policy choices about AI crawlers and robots rules ripple into visibility. Third, the monetization door is cracked open. Cloudflare’s Pay Per Crawl (launched July 1, 2025 in closed beta) uses HTTP 402 Payment Required and Web Bot Auth (WBA) signatures so verified AI crawlers can pay per successful fetch. That makes access programmable instead of binary—block, allow, or charge.
Dates matter for decision-making. Use this quick timeline as your anchor:
- July 1, 2025: Cloudflare’s “Content Independence Day” shift plus Pay Per Crawl beta. HTTP 402 +
crawler-price/crawler-exact-price/crawler-max-price/crawler-chargedheaders defined, with a minimum price of $0.01 per crawl. - November 21, 2025: AWS WAF adds Web Bot Auth support, signaling broader ecosystem adoption of signed bots.
- December 4–5, 2025: Google frames AI search as expansion, not cannibalization; Cloudflare highlights the phenomenal scale of blocked AI scraping since July 1.
Zooming out: this isn’t just a new switch in a dashboard. It’s a structural shift in the web’s value exchange. Historically, you traded crawl access for search traffic; now some crawlers deliver no traffic, and some are starting to pay. Your job is to control exposure without losing the lifeblood of qualified organic users.
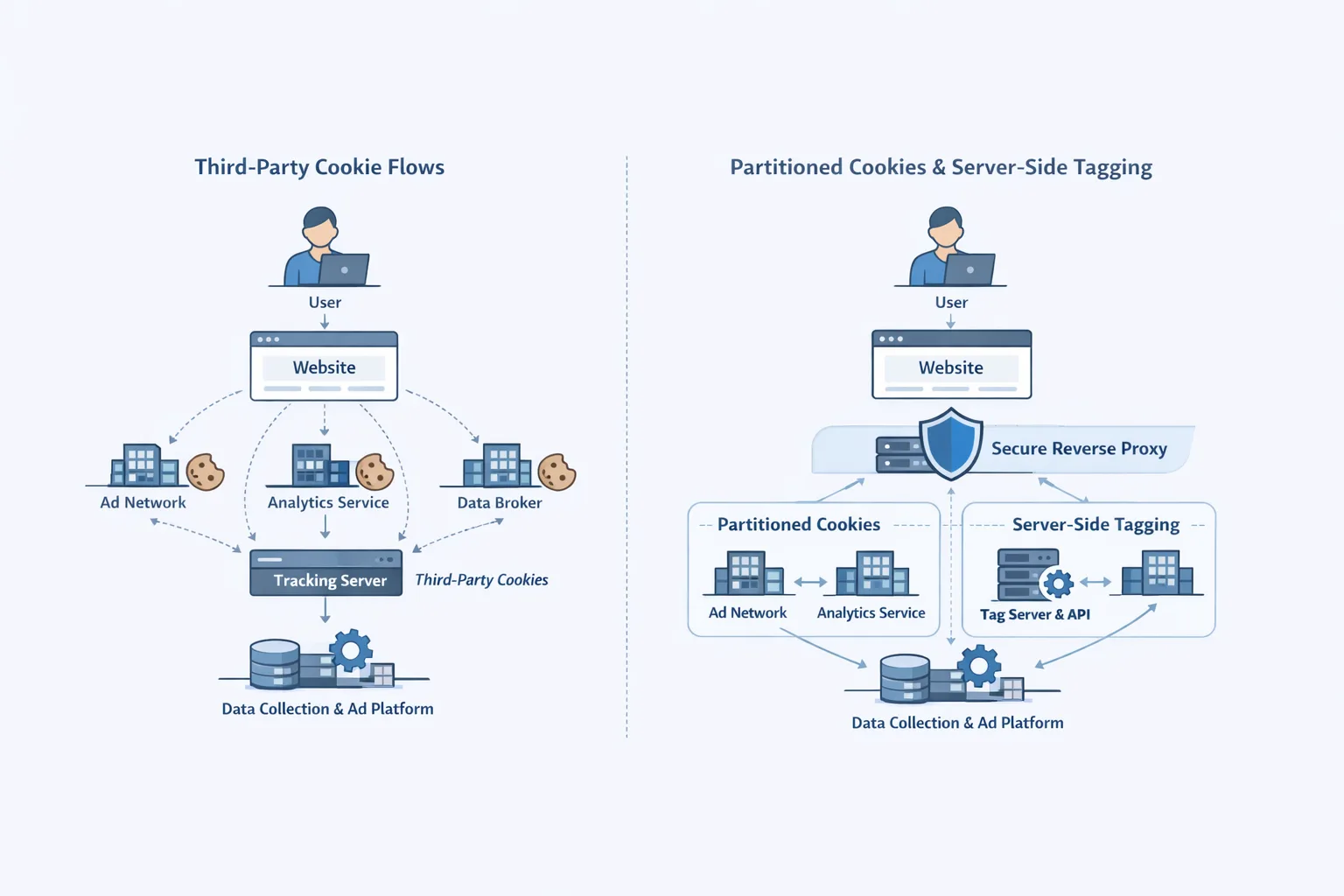
Cloudflare AI bot protection 101
Cloudflare’s stack now has three layers most teams should use together:
1) Block AI Bots (baseline). A one-click policy that blocks known AI crawlers—including those that self-identify—and a growing set of unverified scrapers. You can scope it to all pages or only hostnames with ads if you monetize via display. This is the fastest way to stop the obvious noise.
2) AI Crawl Control (granular). A dashboard to see which AI agents are hitting you, track robots.txt violations, and set per-crawler actions (Allow, Block, or—if enabled—Charge). On paid plans, detections include Cloudflare’s bot scores beyond user agents, catching spoofers that play games with headers.
3) Pay Per Crawl (selective access). In closed beta, it lets you set one price per domain and respond with HTTP 402 if a crawler hasn’t agreed to pay. When it agrees via headers, the edge serves the content and receipts the charge with crawler-charged. It sits behind Web Bot Auth so only signed, verified bots can transact. You can still block specific crawlers while charging others.
Here’s the thing: you don’t need Pay Per Crawl to win. Most sites should start by blocking non-compliant crawlers broadly, then carve out controlled access for the few that demonstrably return value—traffic, attribution, or dollars.
How Pay Per Crawl actually works (in plain English)
Think “HTTP tollbooth.” On first contact, the edge can reply with 402 Payment Required and a crawler-price header. A compliant crawler retries with crawler-exact-price (for that page) or pre-declares a ceiling with crawler-max-price. If the offer meets or exceeds your price, the request succeeds with 200 OK and a crawler-charged header showing the final amount. Everything is signed under Web Bot Auth so spoofed agents can’t sneak through. If you’ve blocked a crawler outright, payment headers won’t override the block.
For most publishers, the value is strategic, not monetary—creating a pressure valve when a compliant AI partner needs access (for example, to keep customers’ agents accurate on docs) without opening the floodgates to everyone else.
Will blocking AI bots hurt Google SEO?
This is the question I hear most. The short version: if you slam the door across the board, you might entangle valuable search features with AI features you intended to block. Google operates multiple crawlers and AI-related user agents, and some experiences blend classic crawling with AI-assisted presentation. A blunt deny-all can reduce visibility in areas you actually want.
Practical approach: keep classic search discovery paths open while you restrict or meter AI training and assistant crawlers. That means:
- Allow conventional search crawlers that demonstrably drive qualified traffic.
- Scope Cloudflare’s Block AI Bots to paths or hostnames where syndication has zero upside.
- Use AI Crawl Control to specifically block crawlers that violate
robots.txtor don’t provide referral value, and consider “Charge” for those willing to verify and pay.
It’s not perfect—some crawlers evolve, and new ones appear weekly—but this gets you out of all-or-nothing thinking. You can revisit settings monthly as clickthrough and revenue data roll in.
Using Cloudflare AI bot protection without losing Search traffic
Let’s get practical. Here’s a 72-hour rollout we’ve used with teams from mid-market publishers to B2B SaaS docs at scale.
Hour 0–6: Baseline and observe
- Enable Block AI Bots globally, then immediately disable it on hosts or paths where you rely on search-driven leads (e.g., blog, docs). Use the “only on ad hostnames” option if display ads matter.
- Turn on AI Crawl Control for visibility. Watch the Crawlers table and flag agents with robots violations or abnormal rates.
- Snapshot analytics: organic sessions by landing page, non-brand keyword clicks, and crawl stats. You need a pre-change baseline.
Hour 6–24: Carve, test, and tighten
- Create two WAF profiles: one strict for content with zero syndication upside (pricing pages, gated content teasers, proprietary data endpoints), and one permissive for public knowledge content.
- In AI Crawl Control, explicitly Block crawlers that don’t respect robots or mask identity. Add custom block responses where helpful (e.g., 403 for violators; 402 for candidates you’re open to charging later).
- Instrument your origin logs to capture user agent, bot score, and path. Alert on sudden spikes or new unknown agents.
Hour 24–48: Protect SEO and attribution
- Keep traditional search crawlers open, but clamp down on bulk scraping of image/CDN subdomains that don’t influence rankings.
- Add referrer validation on API read endpoints to ensure only your site-initiated reads are allowed; pair with token-scoped CDNs for client apps.
- Audit your sitemaps and ensure canonical URLs and lastmod dates are accurate. If you tighten crawl budgets, you need clean signals.
Hour 48–72: Decide on money
- If your content benefits from being inside certain assistants (for example, developer docs), consider requesting Pay Per Crawl access from Cloudflare and set a conservative starting price (e.g., $0.01–$0.05). You can still block bad actors.
- Draft a short policy page describing your AI access stance. Consistency matters for partners and for your support team.
- Set a monthly review: compare organic traffic, conversions, and bot blocks. Adjust per-crawler rules, not your entire site.
robots.txt starter snippet (use with caution)
# Allow traditional web search engines that send traffic
User-agent: Googlebot
Allow: /
# Disallow selected AI training crawlers
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
# Default: block unknown AI bots (won't catch spoofers)
User-agent: Amazonbot
Disallow: /
This is only a hint: many scrapers ignore robots.txt. Treat it as signaling, not enforcement. Cloudflare’s detection and signed bot checks are where enforcement happens.
Framework: the AI Crawler Control Maturity Model
Use this to map where you are and what to implement next:
- Level 0 — Passive: No AI-specific controls.
robots.txtis generic. Logs are noisy. Risk: invisible scraping and polluted analytics. - Level 1 — Baseline Blocking: Cloudflare Block AI Bots on; per-host exceptions for SEO-critical paths; weekly review of AI Crawl Control dashboard. Risk: over-blocking if unmanaged.
- Level 2 — Granular Policies: Per-crawler rules, custom responses (403 vs 402), rate limits by path, verified bot allowlists, and origin instrumentation. Risk: config sprawl; mitigate with change logs.
- Level 3 — Programmable Access: Pay Per Crawl enabled for select partners, Web Bot Auth verification enforced, business rules tied to referral value, and quarterly pricing reviews. Risk: operational overhead; offset with automation.
Edge cases and gotchas
Third-party embeds. Widgets, analytics, and support chat can proxy requests that look like bots. Test with staging tokens and review referrers. Maintain a small allowlist for essential services.
Image and file CDNs. AI agents love static assets for vision tasks. Apply tighter bot rules on file hosts and tune cache keys so you don’t serve to scrapers for free.
API leakage. Public read endpoints (search, listings) are juicy. Add HMAC-signed requests from your front end, enforce token scopes, and rate-limit aggressively. If your mobile app is scraping your own API, fix the client—not your WAF.
Spoofed user agents. Assume sophisticated scrapers forge headers. Lean on Cloudflare’s bot score and WBA verification, not user-agent strings.
Attribution gaps. Some AI assistants paraphrase answers without links. Track branded search demand and direct visits after policy changes to ensure you’re not trading short-term quiet for long-term invisibility.
Data-backed checkpoints for your roadmap
Use these facts when you brief your leadership team:
- Cloudflare reports blocking extraordinary volumes of AI scraping attempts since July 1, 2025—enough to materially impact bandwidth bills and analytics quality.
- Google continues to integrate AI into Search (including follow-up questions and AI-guided sessions), while stating outbound traffic remains a priority. Treat AI and Search as a single surface.
- Pay Per Crawl is live in closed beta with a minimum price of $0.01 per successful fetch and relies on Web Bot Auth signatures to prevent spoofing.
- AWS WAF supports Web Bot Auth as of November 21, 2025 for CloudFront—another sign that signed bots will become table stakes across clouds.
For builders of AI agents: be a good citizen
If you’re on the other side—shipping agents or retrieval pipelines—you need a compliant ingestion story. Support Web Bot Auth, surface a clear user agent and public key, obey robots.txt rules, and respect 402 responses. If your product runs on AWS, the WAF support for WBA makes compliance easier at the edge. If you’re building on Amazon’s model stack, see our take on deploying responsibly in this Nova 2 Omni builder’s playbook.
What to do next (developers)
- Turn on Block AI Bots, then add exceptions for SEO-critical hosts. Verify with a controlled crawl test and Search Console logs.
- Review the AI Crawl Control dashboard weekly. Block repeat violators; add custom 402 responses for potential partners.
- Instrument origin logs with bot score, path, and latency. Alert on new agents and sudden rate spikes.
- Harden static asset hosts and public read APIs with stricter bot policies and token-based access.
What to do next (owners and CTOs)
- Decide your stance: block, allow, or charge. Write a one-page AI access policy your team can share with partners.
- Set a monthly KPI review that includes organic traffic quality, referral diversity, and bot-block success.
- Explore a limited Pay Per Crawl pilot if your content benefits from assistant inclusion. Start at a low price and revisit quarterly.
- Get implementation help if you lack bandwidth. Our team has shipped these rollouts for content, SaaS docs, and marketplaces—see our services and examples in our portfolio, or just contact us.
People also ask
Can I block AI crawlers on only some subdomains?
Yes. Scope Cloudflare’s Block AI Bots to ad hosts or specific hostnames, and use AI Crawl Control per-crawler rules. Keep search-critical hosts more permissive.
Will Pay Per Crawl slow down my site?
No, not for human visitors. The 402 negotiation only applies to qualifying bot traffic. Human traffic and normal crawlers route as usual.
How do I know if a crawler is legit?
Look for Web Bot Auth signatures and verified bot identities. User-agent strings alone are not reliable.


If you’ve been waiting for clarity, you’ve got it. The wave is here, and the tooling is ready. Use Cloudflare AI bot protection to stop the noise, preserve the clicks that matter, and—where it makes sense—turn crawls into contracts.
Want a second set of eyes on your rollout? We share practical guides like this regularly on the Bybowu blog and help teams design policies that protect value without wrecking growth.






Comments
Be the first to comment.