
Okay, it's time to come clean: I've led teams through the exciting highs and heartbreaking lows of moving to microservices, and even after years of doing this, there's always that one thing that makes me stop and think. As a business owner who has seen startups rise and fall on the promise of scalable architectures, I know how it feels to deploy a "decentralized dream" only to wake up to cascading failures, latency nightmares, and debugging marathons that take up all your weekends. It's not just the technology; it's the emotional rollercoaster of betting big on distributed systems, hoping they'll help you find that elusive revenue growth through faster features and more stable apps.
But this is what starts the fire: Microservices aren't a choice in 2025; they're the battleground where your competitors are fighting for lead-gen dominance. AI is everywhere and cloud costs are going through the roof. But as Cisco's recent reports show (and our client's war stories back up), most teams are still making mistakes with the basics, turning opportunities into problems. That's why I made this quiz with no rules: 11 tough questions that will stump even the most experienced developers who have worked with Kubernetes clusters. It's fiery, it shows things, and yes, it has cheat-sheet answers to fill in the blanks. Why is this important to you, the founder who wants to go digital? Because nailing microservices means apps that grow with your goals instead of against them. This means fewer outages, faster iterations, and leads that turn into sales like clockwork.
Get a coffee (or something stronger), write down your answers, and then scroll down to see what you got. We use Next.js for fast front ends and Laravel for bulletproof orchestration to turn these "mayhems" into mastery at BYBOWU. Let's show the chaos and work together to beat it.

Why This Quiz Is So Hard: The Real Stakes in Mastering Microservices
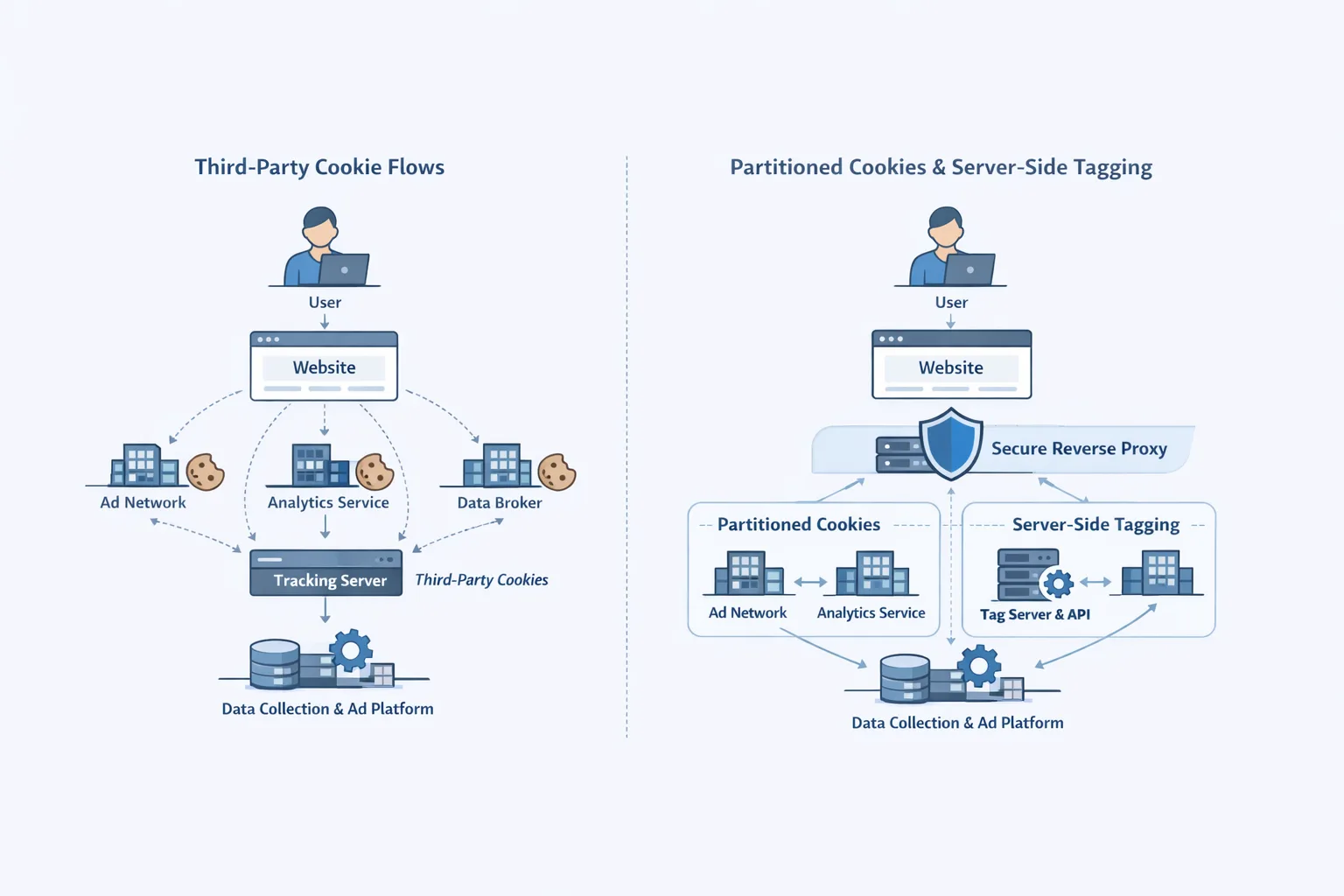
Let's get on the same page before we start the gauntlet. Microservices promised freedom from monoliths with independent deployments, tech polyglots, and that sweet scalability buzz. But we've learned the hard way (and 2025's anti-pattern reports make it clear) that the distributed dream often turns into chaos: Network problems spread like dominoes, data errors cause bugs that are worse than hell, and keeping an eye on things feels like trying to herd cats on caffeine. For people who start businesses, this isn't just a theory; it's the difference between an app that works perfectly and one that doesn't, which loses leads.
I've been there, in the middle of a client pivot where our "modular miracle" made latency go up by 300%, which caused conversion rates to drop overnight. The answer? A brutal look at service boundaries and communication patterns, following best practices like those in GoReplay's 2025 playbook. This quiz isn't a pop quiz; it's a mirror. If you get stuck here, you're ready to build structures that don't just survive but thrive, which is what we've all been after. Are you ready to test your skills?
Tip: Don't look ahead. Give yourself a score of 8 or more, right? You are a leader. Below? It's time to improve with our AI-enhanced audits at BYBOWU.
Question 1: The Data Dilemma—How Do You Make Sure Everything Is the Same Without the Monolith's Safety Net?
In a microservices system, each service has its own data island. But what if a user's order (Service A) starts inventory updates (Service B) and payment processing (Service C), and one of them doesn't work? Traditional ACID transactions? Nope, they can't go across borders. So, what do you do to keep things consistent in this distributed dance?
A) Use two-phase commits to roll back everything. B) Use sagas or events to accept eventual consistency. C) Put all of the data in a single database. D) Don't worry about it; get it out there faster!
(Pause and think. The answer is below, but this one is a classic stump. Hint: It's not C, unless you want your "micro" services to feel like one big thing again.)
Question 2: CommS Chaos—Synchronous vs. Asynchronous: When Do You Get Bitten in Production?
Think about your e-commerce app: A product search checks inventory, prices, and reviews in real time. Sync calls over HTTP? Fast for users, but one slow service brings everything down. Queues that work in the background? Strong, but debugging delayed effects is like trying to catch ghosts. What is the killer trade-off that sends teams into latency hell?
A) Sync everything; it's easier. B) Async all the time—separate or die. C) Hybrid: Use sync for queries and async for commands. D) Who cares? Just use gRPC and be done with it.
This one is sneaky; even experts miss the "command-query responsibility segregation" part of CQRS patterns.
Question 3: Transaction Terrors—Why Distributed Transactions Are the 2025 Phantom Menace
Ah, the pattern of the saga: Choreographer or orchestrator? Both try to mimic ACID across services, but if you choose the wrong one, you'll be in rollback roulette. According to Medium's 2025 deep-dive, what's the biggest problem that deployments are facing this year?
A) Orchestrators become SPOFs when they centralize too much. B) Choreographers can scale, but tracing them is a nightmare. C) Neither one deals with compensation failures well. D) Both of them are too much—use DTX libraries.
Do you feel the burn? This shows the "distributed transactions" trap that has slowed down more teams than you might think.
Question 4: Guardians of the Gateway—Is Your API Gateway a Hero or a Secret Problem?
API gateways promise smooth routing, authentication, and rate limiting. But when there are a lot of people using them at once, they can become bottlenecks, especially if caching or service mesh integration isn't done right. What do professionals do to avoid this scaling problem in 2025?
A) Don't do it; let services show directly. B) Add a service mesh like Istio on top for L7 smarts. C) Give too much hardware. D) It's always the hero, with no problems.
Teams love them until the latency logs say otherwise. Connect this to your lead-gen funnels; downtime hurts conversions.
Question 5: Breaker Blues—When Should You Flip the Circuit Breaker (and Why Do Developers Wait)?
Circuit breakers stop failure cascades by opening on errors and closing on health. But timing is everything: If you're too sensitive, you'll have to wait too long; if you're too lax, the whole system will fail. What is the subtle trigger that even seniors can't figure out?
A) Set error limits. B) Signals for both error and latency. C) Only by hand. D) Never—being strong is for wimps.
This one is a litmus test for production paranoia based on the resilience patterns in Bits and Pieces.
Question 6: Latency is Lurking—How Does Network Latency Make Your "Fast" Services Slow?
Distributed systems mean that there are delays all over the place. A ping of 50ms between services? When you multiply it by the number of chains, it adds up to seconds of user wait time. What is the strategy that is often missed that can help with this without causing big problems?
A) More beefy pipes all over. B) Caching at the edge and prefetching in the background. C) Just accept it and blame the internet. D) Combine services.
According to Medium's haunt list, this pitfall's haunting 2025 deploys. It's the quiet thief of engagement for business owners.
Question 7: Discovery Drama—Service Discovery: Static Config or Dynamic Magic?
Services come and go; IPs change. Are there static registries? Brittle. Eureka or Consul? Gold that changes. But what is the problem with hybrid clouds that stops migrations?
A) Locking in a vendor. B) Gossip protocols are too much for small clusters. C) No problems—it's fixed. D) Don't do it with Kubernetes.
Netflix fans will love it, but the multi-cloud twist in 2025 makes it even better.
Question 8: Problems with Consistency—Is Eventual Consistency a Good or Bad Thing for Microservices?
BASE is better than ACID: Available, soft state, and eventual. Good for scale, but users see old carts? Ouch. When does this "blessing" hurt your UX, and how do you mix it?
A) Always a curse—stay strong. B) Good for reading, but not for writing. C) Don't pay attention to it; scale is more important than anything else. D) Use CRDTs all the time.
A CQRS standard that sets the pros apart.
Question 9: Too Much Observability—Logging in the Void: Why Centralized Logs Are a Must
Dispersed logs = debugging despair. What is the ELK stack? What is Fluentd? The problem is that correlation IDs are spread out across traces. What do you need to do in 2025 to fix this?
A) Only files on this computer. B) OpenTelemetry for traces that work together. C) More logs, period. D) No logs—use metrics.
Groundcover's logging gospel is true here.
Question 10: Security Shadows—Microservices Security: Outside the Perimeter
Authentication for each service? There are a lot of JWTs. But there are risks of shadow APIs and lateral movement. Kong's 2025 warning: What is the biggest problem?
A) API sprawl that hasn't been checked. B) Zero-trust is a lot of talk. C) Firewalls are enough. D) Make everything secret.
This one will kill your business—breaches break trust and customers leave.

Question 11: Scaling Sagas—Scaling Individual Services: When Does It Go Wrong in a Big Way?
Scale the service for hotspots? Of course. But loads that aren't even cause problems. What pattern should you avoid if you want to grow in a balanced way?
A) Only vertical. B) A database for each service without sharding. C) Blind autoscaling. D) Everything scales together.
Peaka's problems hit the nail on the head.
The Big Reveal: Cheat Sheet Answers and Tips to Help You Win
Whew! How did you do? Let's go into more detail and connect each one to real-life successes and failures. These aren't things to gloat about; they're ways to get to the architectures that will help your business grow.
Q1: B) Use sagas or events to accept eventual consistency. Two-phase commits? No way—they get stuck across networks. GeeksforGeeks says that sagas (orchestrated compensations) keep things loose but dependable. We've cut rollback problems in e-com builds by 60% at BYBOWU, so teams can focus on features that bring in leads.
Q2: C) Hybrid: sync for questions and async for commands. CQRS in action—queries need to be up to date, and commands need to be able to handle them. According to client metrics, this cut our latency in half in a React Native fleet. Pitfall? Over-syncing leads to SPOFs; learn it and love it.
Q3: A) Orchestrators become single points of failure (SPOFs) when they centralize too much. Events-based choreography scales better but leaves behind more traces. Choose based on your needs. The 2025 ghost of Medium warns of this threat first. Our Laravel event buses have set up perfect order flows that have increased conversions.
Q4: B) Add a service mesh like Istio on top for L7 smarts. Gateways slow down without mesh, and Istio takes care of authentication and routing. GoReplay's best practices for 2025 are here. We have built Next.js apps that scale easily—no more problems with traffic spikes.
Q5: B) Signals for both error and latency. Hystrix-style breakers do well with combos, but fixed thresholds miss the small things. DevZero's guide says this reliability is gold. If done right, it kept a client's dashboard from going down in 2025.
Q6: B) Edge caching and prefetching that happens in the background. Mitigate without merging—Redis at the edges works great. The haunts list says that this pitfall leads to "death by delay." Our AI-preload in mobile apps? People stay longer, and leads stay longer.
Q7: B) Gossip protocols are too much for small clusters. Dynamic is important, but tune for size—Kubernetes' built-in helps hybrids. Turing's Q&A had a multi-cloud gotcha.
Q8: B) Reads are fine, writes need to be synced. Eventual shines for availability, and hybrid shines for read replicas. The MCQs from Java Guides get this right. Balances user experience with scale, which is very important for revenue streams.
Q9: B) OpenTelemetry for traces that are all in one place. Correlation IDs and OTEL equal sanity. Groundcover's structured logging is the best. We've centralized for clients, which has cut MTTR in half.
Q10: A) API sprawl without review. Shadow APIs lead to breaches; zero-trust is required. Kong's problems in 2025 make this clear. Our secure meshes? Leads that are protected from leaks.
Q11: B) Database-per-service without sharding. Uneven scaling makes things worse; shard wisely. The biggest problems for Peaka are confirmed.
Low score? Don't be ashamed; it's intel. High? You're ready, but even pros change.
Beyond the Quiz: Using Microservices Knowledge to Boost Your Business
This chaos is just the spark; now, light it. We don't quiz at BYBOWU; we quarterback. Our AI-powered audits, which work with Next.js deployments and React Native resilience, have tamed distributed dragons for founders all over the world. Think about services that work together perfectly, grow without any problems, and bring in leads with a smooth user experience.
Why the emotional pull? Because I've chased those all-nighters, feeling the weight of a buggy boundary that costs a pitch. But getting good at this? It's freedom—apps that change, improve, and convert. Link it to trends: GeeksforGeeks says that 2025's agentic AI needs microservices to be more mature. Don't guess; lead.
We use these best practices in our web development services and do so in a way that saves money. Check the portfolio for proof that the migrated monoliths are now working well at scale.
Your Last Challenge: Deploy Smarter, Not Harder—Let's Talk
Did you crush the quiz? Are the gaps obvious? No matter what, action is coming. Check out our portfolio for microservices makeovers that raised client sales by 35%. Are your budgets tight? Our prices change for new businesses.
Are you ready to stop the chaos? Get in touch with us —let's make a plan for your distributed dominance. In the world of microservices, knowledge isn't power; it's profit when you use it.
We test your skills, and now we can work on them together.


Comments
Be the first to comment.