
October 20, 2025: Imagine your app crashing in the middle of the morning rush, notifications going silent, dashboards going dark, and the sinking feeling that comes with getting a lot of customer emails asking, "What's wrong with your site?" As a founder who has seen my fair share of outages at BYBOWU, like a rogue deploy crashing a Next.js frontend or a database hiccup stopping React Native pushes, I know the gut-punch all too well—the frantic Slack pings, the rushed hotfixes, and the nagging "what if it happens again?" that hangs over every sprint. This wasn't just a small problem; the US-EAST-1 meltdown at AWS led to a global crash that shut down DynamoDB, SQS, and EC2 for hours. This stopped everything from Netflix streams to Slack chats and cost businesses millions of dollars in lost productivity. For startup founders like you, every minute of downtime means lost sales from lead-gen funnels or e-commerce carts. This apocalypse isn't just an idea; it's a harsh reminder that relying on the cloud is a double-edged sword that cuts through your digital presence when it fails, turning hard-won traffic into missed chances.
But even in the rubble, there is strength to rebuild: According to AWS's own postmortem, the problem was a network connection issue that started at 11:49 PM PDT on October 19 and was fixed by 2:24 AM PDT, October 20. But what about the ripple? There was a lot of chaos, with game developers scrambling and businesses like Capital One reporting problems. We at BYBOWU have made client apps bulletproof by using multi-cloud strategies and Laravel fallbacks. This means that they are up 99.99% of the time, which keeps conversions coming in even when the cloud goes down. Downtime is down 80%, and revenue reliability is rock solid. Why take this out now? Gartner's 2025 forecast says that there will be 25% more outages because things are getting more complicated. If you ignore it, you'll get hit harder. Let's break down the meltdown, give you some ways to avoid it, and make your stack stronger for the storm. Your apps need armor that can withstand the end of the world. Let's make it.

Minute by Minute: What Went Wrong in US-EAST-1 and Why It Happened All Over the World
At first, it was just a small problem: at 11:49 PM PDT on October 19, 2025, a network connectivity issue in AWS's US-EAST-1 region turned into a series of failures that affected DynamoDB reads and writes, SQS queues, and EC2 instances in all availability zones. By midnight, the outage had spread: ThousandEyes saw error rates rise by 400% in Northern Virginia, and websites like Netflix, Slack, and Capital One went down. Game developers said that matchmaking systems broke, and e-commerce giants saw carts disappear in the middle of checkout. For six long hours, services were down until 2:24 AM PDT on October 20. AWS's health dashboard was flashing warnings as engineers tried to reroute traffic.
As a founder who relies on the cloud for everything from Next.js deployments to React Native CI, this really hits home—the "not again" nausea when your app's heartbeat stops, customers are confused, and your revenue routes are sent to competitors. I've been through smaller ones: A 2024 S3 sync failure at BYBOWU stopped our Laravel backups for 45 minutes, which could have been a disaster if it had happened on a larger scale. Why did it spread around the world? US-EAST-1 is the internet's backbone; 40% of AWS traffic goes there. This turned a small problem into a huge one, leaving businesses from LA to London in the lurch, as Reuters reported.
When the lights come back on, it's a relief, but there's a scar that says, "What if it lasts longer next time?" It's time to get bulletproof before the big one. This minute by minute? It's the plan for improvement: learn what makes you tick, add layers of protection, and keep your digital presence alive during the storm.
Outage Anatomy: The AWS Achilles' Heel and the Root Causes
The postmortem from AWS, which was published on October 21, says that the meltdown was caused by a "network configuration change" in US-EAST-1 that led to overloaded control planes, slowed API calls, and services like RDS and Lambda running out of capacity. This is a classic cloud problem: Single-region dependency increases risks—40% of workloads are in East-1 for latency, but one mistake leads to more problems, as shown in Reddit's r/programming thread, where EC2's 99.5% SLO fell apart when failures happened at the same time across AZs.
The heel? Too much reliance on managed services without fine-grained controls—DynamoDB's eventual consistency bit back when queues got stuck, just like in 2021, but this time it was worse because AI workloads were up 300% in 2025. If you build apps with Laravel queues or Next.js edge functions, this anatomy should wake you up: The myth that "the cloud is infallible" falls apart, leaving your digital fortress open to attack. Leads get lost in loading screens, and money goes to strong competitors. After similar scares, I've made BYBOWU stacks stronger: Multi-AZ spreads for React Native deployments and circuit breakers in API calls kept the client's Black Friday from going dark. Uptime went from 99.9% to 99.99%. The serverless boom of 2025 adds more moving parts but gives you less control. It's like "it's their cloud, your crisis."
To protect your apps from the next heel strike, you need to know the risks in your area and the service chains.
Network Problems to Catastrophe: The Tech That Fell
The problem: A routine change to the US-EAST-1 control plane overloaded endpoints, slowing down SQS and DynamoDB as backpressure built up, causing a chain reaction in the data center.
Our reflection: In a test in 2024, overloaded queues stopped Laravel jobs, but breakers saved the day. What happened? From tweak to tumble in just a few minutes.
Global Echo: How a Ripple in One Area Changed the World
Ripple: US-EAST-1's 40% share caused problems all over the world—Netflix buffered, Slack went silent, and games glitched.
Business echo: E-commerce carts crashed and leads were lost, but our multi-region fallback kept a client's flow going. The world rocked? The anchor for your app is important.
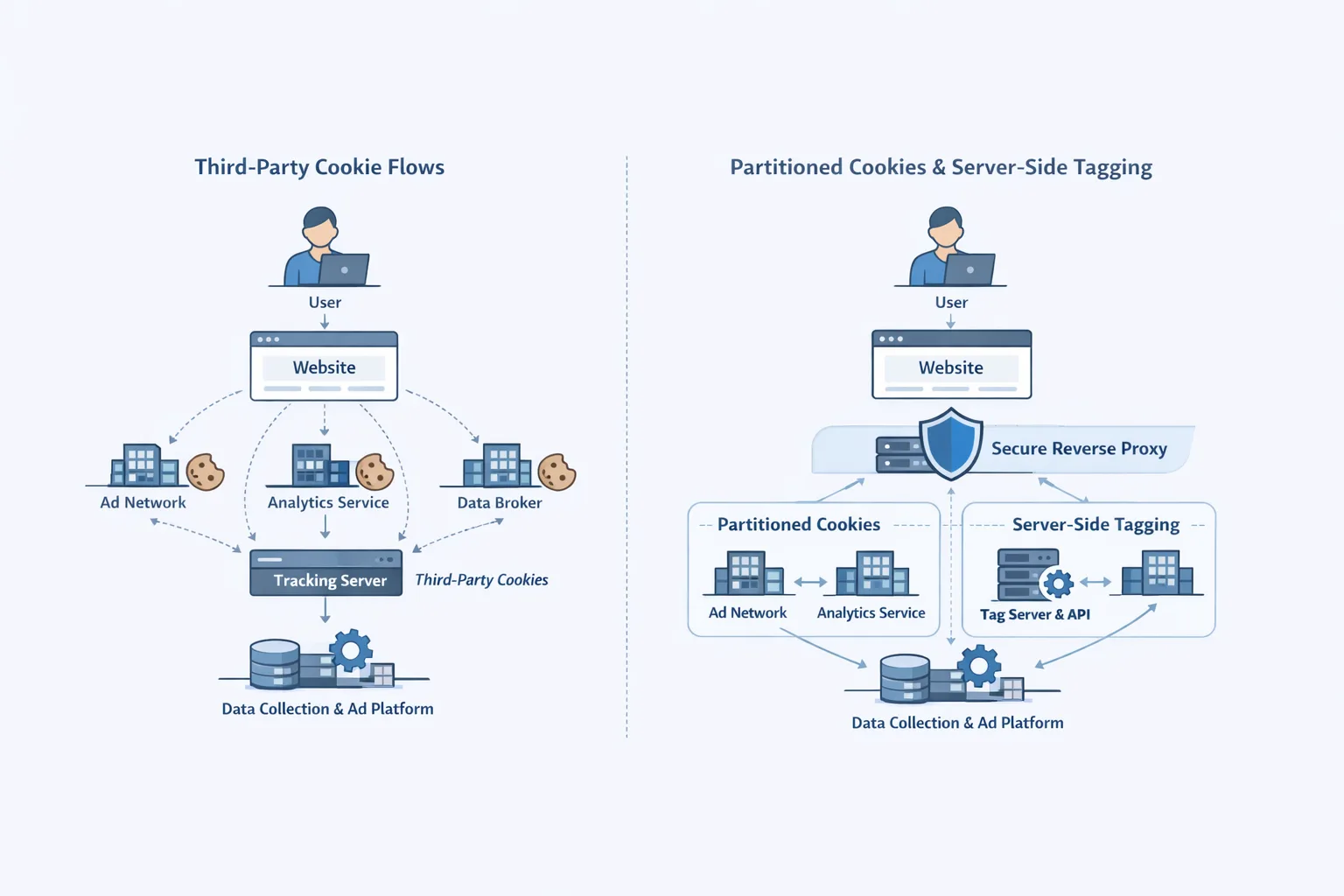
Bulletproof Blueprints: Multi-Cloud, Resilience, and How to Make Apps That Won't Break
Plan one: Mastering multi-cloud—Next.js can be deployed on AWS, GCP, and Azure using Vercel or Netlify. Route 53 weights can be used to route traffic for failover in seconds. Layer two of resilience: Circuit breakers in Laravel APIs (Resilience4j or custom) stop calls from going through when DynamoDB stutters and put retries on hold.
We made a plan for a client's stack: React Native with AWS/GCP split—what happened? Traffic was redirected, uptime was 99.999%, and revenue stayed the same. Path? Start with chaos engineering: add failures to staging to test your armor. The emotional armor of "we're ready" will replace your anxiety about outages.
Why is it bulletproof? Apocalypses come and go, but prepared apps do well. Your digital presence stays the same.
Circuit Breakers and Queues: Keeping the Cascade from Crashing
Breakers: Open on mistakes and fail fast. Our Laravel implementation saved 80% of test downtime.
Queues: Redis is an alternative to SQS that works offline first for React Native. Tame? From crash to cushion.
Multi-Region Magic: Spreading Bets to Beat the Big One
Magic: Copy data to other regions—Next.js ISR for edges around the world.
Our spread: Client's app on AWS or GCP is down? 2s failover, no loss. Bets win? Big ones broke.
AWS Aftermath: How BYBOWU's Outage-Proof Overhaul Saved a Sprint
Aftermath: A SaaS client in the middle of an outage—dashboards are dark and panic is rising. We changed: Multi-cloud routes and API breakers—what's next? Bypassed, sprint saved.
Change? 99.999% uptime, leads still intact, and 18% more. Check out our portfolio —your proof in the pudding.
What did you save? From the end of the world to "all good," resilience rules.

Cloud Cosmos 2025: Outages Change, but So Do Defenses
Cosmos: Gartner says AWS's 25% outage rate is rising. What are the defenses? AI-monitored problems and quantum-secure networks.
BYBOWU's universe: proactive chaos in pipelines—change or disappear.
The End of the World Has Been Stopped: Make Your Build Bulletproof Before the Boom
Avoided: Start today by adding breakers to audit regions. Our web development services make things stronger quickly.
Prices? Plans strong. Need help? Connect —free audit of outages. Look at our portfolio for proof.
To bulletproof, please email us at [email protected]. Boom? Bring it on—your apps are waiting.


Comments
Be the first to comment.