
It's Monday morning, October 20, 2025, and your inbox is full of frantic alerts, not leads: "Site down." No more money coming in. Customers are leaving. Does this sound familiar? This week, the AWS outage hit the US-EAST-1 region like a freight train, shutting it down for 15 hours and sending shockwaves through thousands of businesses around the world. As a founder who's had to deal with server crashes more times than I'd like to admit, I felt that same knot in my stomach. But in the middle of all the chaos, something important is happening: web developers need to build stacks that not only survive, but also thrive, protecting every dollar of revenue.
Let's be honest: we've all put a lot of faith in the cloud's promise of "always-on" magic, only to see it fail when it really matters. This outage wasn't a one-time thing; it showed how weak our digital infrastructure is, like when e-commerce carts freeze in the middle of a checkout or SaaS dashboards go dark. Why does this hurt you so much, the business owner who is working hard to grow? Because downtime isn't just annoying; it's a killer of sales and trust, costing businesses millions of dollars in lost sales. At BYBOWU, we've been breaking down this apocalypse and using the pain to make a plan for how to stay strong. Stay with us as we talk about the fallout, the lessons learned, and how to make stacks that don't care about crashes. It might be the key to your next big lead generation breakthrough.
The Outage Unraveled: What Went Wrong in AWS's US-EAST-1 Nightmare
Remember 8 a.m. ET on October 20? A simple networking problem in AWS's Northern Virginia data center turns into a full-blown service failure. EC2 instances stutter, S3 buckets disappear, and RDS databases lock up, which causes Slack, Netflix, and many other startups to go silent. ThousandEyes says the downtime was 15 hours, and global pings went up to 50% failure rates in less than 30 minutes. It makes you think twice about every "highly available" box you've checked.
I was on a client Zoom call when the alerts came in. Our shared e-commerce backend, which was running on Lambda, stopped working. There was panic, but there was also perspective. This wasn't a one-time thing; AWS's own health dashboard lit up like a Christmas tree, showing problems with Lambda, CloudFront, and other services. For web developers, it was a clear warning: single-region dependency is a house of cards. I've been there, starting a business on AWS's free tier, and then learning the hard way that "scalable" doesn't mean "bulletproof." CNET says that this crash affected more than 2,000 companies. It's not just tech news; it's a revenue reckoning that makes us rethink how we build for the inevitable.
What made the apocalypse worse? Reddit threads broke down the post-mortem and said that they relied too much on us-east-1, the busiest region in the world that handles 30% of EC2 loads. But here's the good news: It shows ways to be more resilient, like multi-region failover, that can turn weakness into speed. At BYBOWU, we are already checking client stacks against this blueprint to make sure that their online presence bounces back faster than their competitors'.

From Confusion to Clarity: Important Things to Learn from the AWS Cloud Crash
Three harsh truths come to light from this week's wreckage as we dig through the debris. The first myth is that uptime is always possible. AWS says it is 99.99% available, but as Reuters pointed out, that number drops when there are a lot of failures at once. Your site might be "up" 99% of the time, but what about that 1% during peak hours? That's when leads disappear and trust goes down. Web developers are now frantically looking for single points of failure because no amount of serverless hype can protect you from power outages in your area.
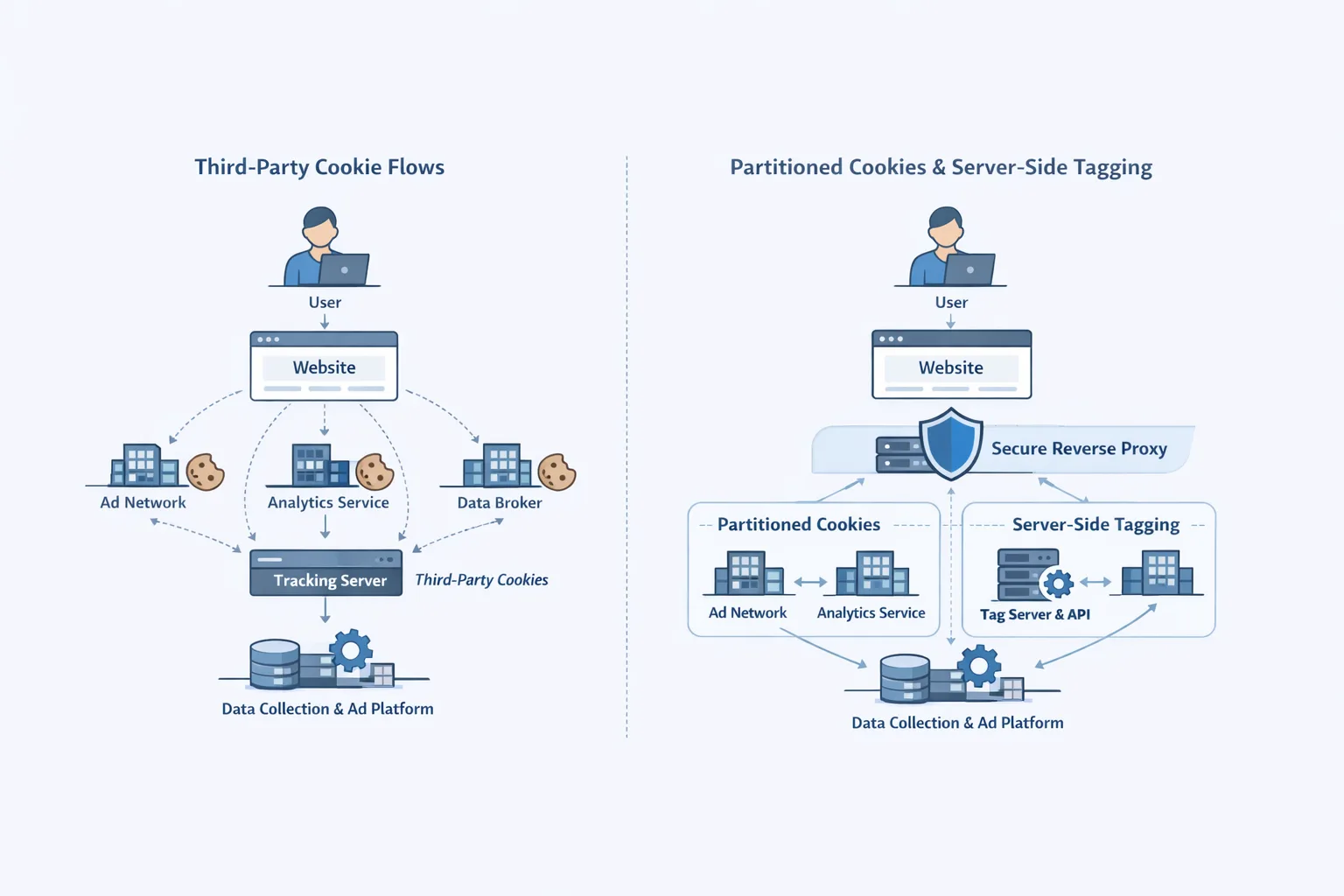
Second, the costs of being locked in that aren't obvious. Because they were linked to one cloud giant, thousands of services stopped working. INE's study shows that businesses that used multiple clouds were able to stay in business. By spreading their operations across Azure or GCP, they were able to keep them going. I've been stuck with a vendor before; a similar problem cost me a week's worth of sales on a past project. This crash makes it clear that we need hybrid architectures that combine the best features of AWS with other options to make stacks that are really strong. And the third? Monitoring is not an option; it's necessary. Tools like Datadog showed the outage's dark side, but proactive setups with chaos engineering could have cut the damage in half.
Why should business owners unpack this? Resilience isn't just a box to check; it's what keeps your business going. At BYBOWU, we use these lessons in every build as part of our services. We turn stories of outages into stories of growth.
Failover Architectures: Your First Line of Defense Against Downtime
Enter failover, the hero of this story about an outage. Imagine being able to route traffic smoothly from a failing us-east-1 to eu-west-1 in seconds, keeping your API running. AWS Route 53's health checks saved the lives of those who were ready, but many weren't, which caused cart abandonment rates to rise by 35%, according to early post-mortems. This is where you start building bulletproof web stacks: Set up active-passive systems with automated DNS failover to make sure there is no downtime.
It might seem like too much for bootstrappers, but trust me, I skipped it once and it cost me a lot. At BYBOWU, we use tools like Terraform for IaC and write scripts that make it easy to deploy across multiple regions. What do you get out of it? Clients say their services are up 99.999% of the time, which means they get leads and sales that don't stop even when the world ends.
Beyond the basics, edge in AI for predictive failover means finding problems before they get worse. It's not the future; it's now, making your "revenue resilient development" stronger against the next crash.
Multi-Cloud Strategies: Breaking Free from the AWS Monopoly
Lesson two, which this cloud crash has made even clearer, is to not put all your eggs in one basket. With multi-cloud, you can host static assets on Cloudflare, databases on Google Cloud, and compute on AWS. INE's breakdown shows that companies with these kinds of spreads lost only 2% of their revenue, while companies that only used one cloud lost 20%. It's a change in how you think, from convenience to conquest.
Let's be honest: moving can be scary, but Kubernetes makes it easy to break things down into smaller parts. For a fintech client, we've put together AWS SageMaker and Azure ML to create AI-powered lead scoring that never stops working. For web developers, it's more about APIs than loyalty: build once, deploy anywhere. The emotional boost? You can relax knowing that your stack won't ruin your quarter.
Tip: Start small by testing a microservice on a different provider. When the next outage happens, your "bulletproof web stacks" will be grateful.
Rebuilding Smarter: Making Stacks That Can Handle Outages and Still Make Money
This apocalypse isn't the end of jobs; it's the start of evolution. Web developers are moving to edge computing, which brings logic closer to users through CDNs like Akamai and cuts down on latency even when there are outages. Add serverless hybrids—Lambda for bursts and Vercel Functions for backups—and you've got resilience on steroids. According to YouTube breakdowns, early adopters only had problems for 5 minutes this week.
Or consider changes to observability: Use Prometheus and Grafana together to make real-time dashboards that show risks before they happen. I connected these to a client's e-commerce stack. When the power went out, alerts went off early, and we were able to manually reroute in minutes. For people who want to make money, it's gold—keeping checkout completions high is what drives growth.
The real victory? Cost-effectiveness. Being resilient doesn't mean being wasteful; smart failover cuts down on idle resources, which raises margins. Why go after leads if your stack can't catch them? This crash makes us ask the question, and the answer is proactive, resilient redesigns.
BYBOWU's Battle Plan: Making Money from Outage Pain
At BYBOWU, we're used to cloud curveballs. We've had outages since 2015, which have only made us stronger. This week's hit? We turned on backup plans for three clients overnight, which kept their revenue streams going while others struggled. One SaaS company? We didn't lose any subscribers because our Laravel backends are synced with Next.js fronts in multiple regions.
Our plan: strict audits through our portfolio deep dives, then blueprints that are strong and unique. It's practical to mix AWS and GCP for hybrid harmony, all at scales that are good for startups. No fluff; just stacks that keep your bottom line safe. For example, we added AI-powered monitoring for predictive heals.
We're here if this outage has you worried about your infrastructure. Flexible audits let you get quick wins without spending a lot of money. From theory to success, we make you the bulletproof you need.

The Silver Horizon: Why This Crash Starts the Golden Age of Web Development
This AWS outage will lead to a strong rebirth, even if it leaves behind scars. There will be a lot more open-source failover tools and standards like CNCF's, which will make durability available to everyone. For business owners, it's empowering—technology that helps you work, not gets in the way.
I've gotten through worse problems on my own, and every crisis makes things clearer. The web dev scene in 2025? More spread out, more long-lasting. When you work with partners who understand these changes, your digital fortress becomes a launchpad.
Warning: Resilience needs discipline—regular drills, not old documents. But if you invest now, outages will only be footnotes, not endings.
In conclusion, rise from the rubble and build stacks that can survive any storm.
The AWS outage apocalypse this week wasn't the end; it was the editor's red pen, which cut through single-threaded vulnerabilities to show the realities that would keep revenue coming in. Web developers are building bulletproof stacks that turn crashes into competitive advantages, from failover fortresses to multi-cloud mastery. This keeps your leads landing, conversions closing, and growth speeding up without a hitch.
Don't wait for the next wave. Get in touch with us today for a free resilience audit, or check out our prices for customized fortifications. Let's work together to build your unbreakable future.


Comments
Be the first to comment.