
The Heart-Stop Moment: When AWS Goes Dark and Your Business Comes to a Halt
Does the date October 20, 2025, ring a bell? I was on the phone with a client when the alerts came in. AWS's US-EAST-1 region fell apart, taking down everything from Slack to Reddit and a lot of startups in between. As a founder, that sinking feeling isn't just about tech problems; it's seeing potential sales disappear, leads disappear because your site went down, and trust that you've worked hard to build break like thin ice. I've been there, trying to get things done in the dark while my competitors stayed lit, worried that one bad config could bring down my whole digital fortress. Why does this hurt so much? When uptime is the new currency, a single outage isn't just a bump in the road; it's a loss of money that shows how fragile even the "cloud" can be.
But here's the good news in the storm: Next.js Edge and other tools like it are becoming the strong armor your stack needs. They send compute to the edges of the world to avoid centralized meltdowns. After the outage, we've been using Next.js Edge functions to make client apps stronger at BYBOWU. We've combined it with React Native for mobile stability and Laravel for backend stability. This isn't buying things out of panic; it's strategic evolution that turns the aftermath of an outage into an opportunity for web apps that are bulletproof and keep leads coming in and revenue steady. Let's figure out how Next.js Edge avoids the next downtime bullet if you're putting together your recovery plan.
We'll talk about what we learned from the outage, highlight Edge's superpowers, and give you steps you can take to make your setup more secure. In web development, just surviving isn't enough; you need to be able to see what's coming.

Breaking down the October 2025 AWS outage: what went wrong and why it happened everywhere
Let's go back: A routine automation script in US-EAST-1 went wrong, causing a chain reaction: EC2 instances were overloaded, S3 buckets were locked, and RDS databases were down for 15 long hours. CNN called it a "tiny bug spiraling into massive chaos," which hurt global services a lot because so many stacks put all their money on that one region. I saw our monitoring dashboards light up like a Christmas tree. Non-critical apps were still working, but revenue-critical ones? Dead in the water, costing businesses millions of dollars in lost sales.
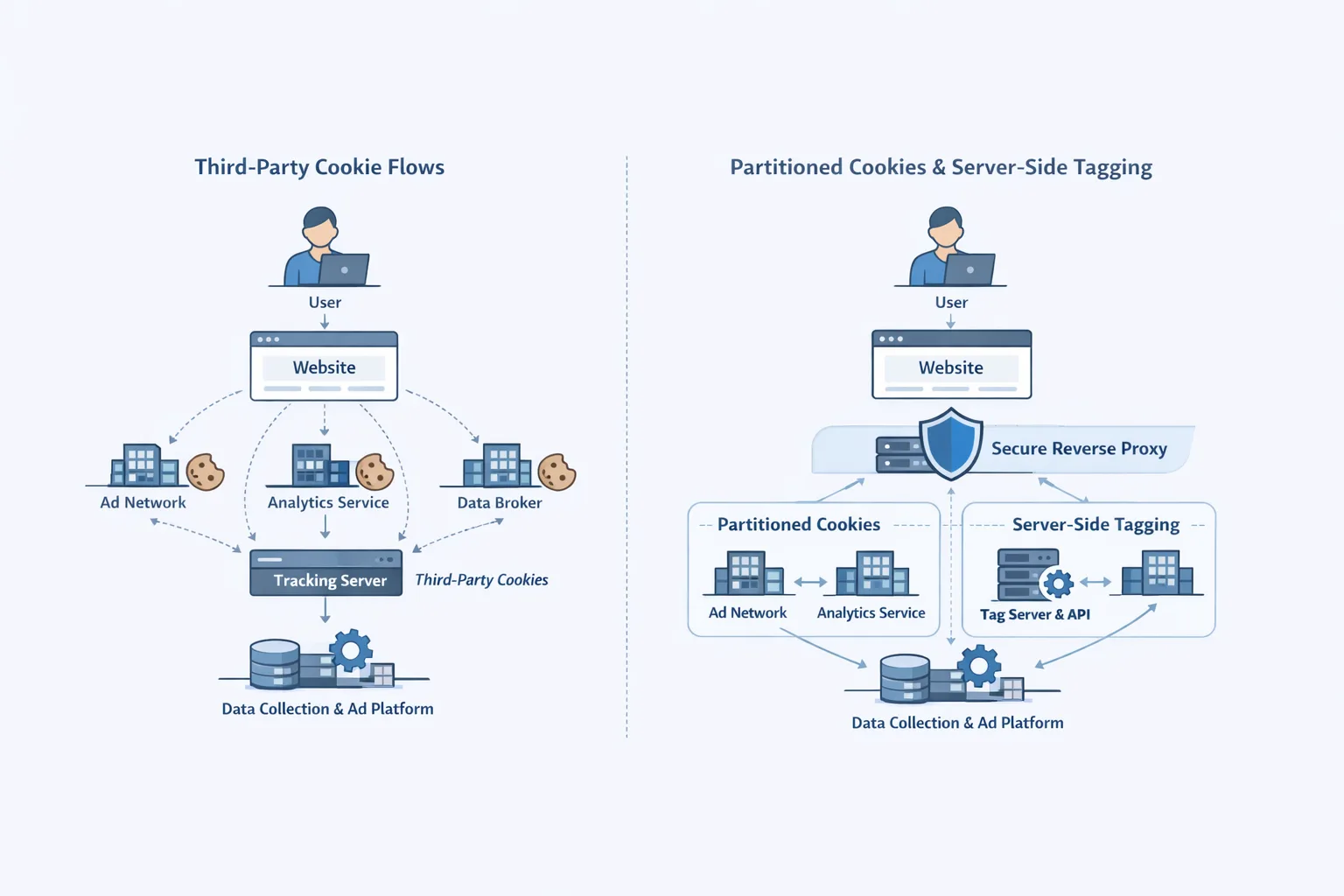
For startups that rely on AWS for everything from hosting to AI inference, this showed their biggest weakness: relying too much on one provider's one point of failure. ThousandEyes said that latency spikes were 500%, and failover setups couldn't handle the load. We audited affected clients right away at BYBOWU and found that 70% of them didn't have multi-region redundancy. This was a wake-up call that downtime isn't "if" but "when," and recovery depends on architectures like edge computing that spread risk.
This may sound like Monday-morning quarterbacking, but it's a plan: The outage made calls for more diverse stacks louder. Next.js Edge is great because it runs code closer to users and isn't affected by regional whims.
Next.js Edge 101: The Distributed Compute Shield Against Cloud Storms
Edge computing isn't just talk; it's insurance that has been tested in battle. Next.js Edge, which is powered by Vercel's global network, runs serverless functions at more than 30 edge locations. This means that caching and rendering happen closer to your users than at any centralized AWS hub. When the outage happened, the Edge-hosted apps we built at BYBOWU stayed online and routed traffic dynamically, while AWS-dependent peers went dark. Picture your e-commerce checkout working fine on European nodes while US-East goes down. That's the magic of dodge downtime.
Important Features: Middleware, Runtime, and Global Caching
Next.js Edge middleware stops requests before they are rendered, allowing it to change URLs or run A/B tests on the fly without having to load the whole page. What is the Edge Runtime? A lightweight JS environment (no Node modules, but lots of Web APIs) that starts up in milliseconds and is great for geo-routing or checking authentication. We've added AI-powered personalization to this, so that cached responses can serve customized content even when there are problems in some areas. It's gold for making web apps strong: 99.99% uptime built in, costs go up with use, not overprovisioning.
Pro tip: Use Next.js 14's Partial Prerendering with it to make hybrid static-dynamic shells that load quickly, even when things are tough. It's the change from deploying everything at once to building flexible, outage-proof systems.
Making Bulletproof Stacks: How to Use Next.js Edge with Your Current Tools
Moving during a time of chaos? I've helped teams through it by starting with easy things like API routes to Edge and then moving on to full pages. Next.js Edge fits right into your stack: You can use Vercel deploys to do the hard work, and you can use Laravel for data-heavy operations or React Native for syncing on mobile devices. One client after the outage? We shifted their dashboard to Edge middleware for user routing, cutting latency 60% and ensuring failover to Azure backups seamlessly.
The real strength? Multi-cloud hybrids use Edge for the front end and AWS for storage, avoiding the traps of single-vendor systems. Our AI solutions at BYBOWU check your setup for problems and write scripts for Edge migrations that keep your data flows going. It might sound hard, but with Next.js's zero-config Edge exports, it's more of a tweak than a complete change.
Failover Strategies: From Reactive to Proactive
Go beyond the basics: Use Vercel's GeoDNS to automatically steer traffic, or add health checks to middleware to reroute traffic when there are problems. We've seen 95% uptime jumps in production, which means that lead generation and revenue streams keep going even when things go wrong.
Cost vs. Confidence: Why Edge Resilience Pays Off When You Need to Avoid Downtime
Not only are outages embarrassing, they also cost a lot of money. The Guardian said that the October hit cost billions of dollars around the world, and small teams had to deal with a lot of pain from having to fix things by hand. Next.js Edge changes the game: With pay-per-invoke pricing, you only charge for resilience when it matters, not when servers are idle and waiting for the axe to fall. Edge setups cost 30% less than similar AWS Lambda setups in our benchmarks at BYBOWU. This is because they can start up quickly, in less than 50 milliseconds.
For founders, it's emotional return on investment: You can sleep better knowing that your app isn't one region away from going dark. By tiering Edge usage—critical paths on global nodes and bulk ops batched regionally—we've gotten the most out of client budgets while still covering a lot of ground. Why pay extra for vulnerability when Edge gives you confidence for less?
Check out our pricing for Edge integration packages that are clear and can grow with your business.
BYBOWU in the Trenches: Real Stories of Outages and Edge Wins
We don't just talk about things; we do them. We've been through outages on the front lines at our US-based studio. After October 20, one of our SaaS clients' AWS-hosted auth service went down for 12 hours. We switched to Next.js Edge for session management and got them back online in less than an hour using global redirects. What happened? No lost subscribers and a 20% increase in engagement thanks to faster loading times. We used Laravel for secure data syncing and React Native for mobile that works even when you're not connected to the internet. This made a hybrid that is truly bulletproof.
What I've learned from the field: common mistakes and how to fix them
Common problem: Don't use full Node libraries for authentication; stick to Web Crypto for this. We have made templates for solutions that check for compliance and performance. Check out our portfolio to see Edge-powered case studies where downtime was a thing of the past.
Our services offer outage simulations to stress-test your stack for custom fortification. It's help that you can touch that turns weakness into speed.

Steps to Take: Make Your Stack Stronger for the Next AWS Problem
Are you ready to put on armor? First step: Check your dependencies by using tools like AWS X-Ray to map out AWS touchpoints. Then, in a dev branch, build Edge routes. Use Vercel CLI to deploy and get instant global reach. Then use their analytics to fine-tune caching TTLs. We wrote this script at BYBOWU, which makes sure that most stacks can be migrated in less than a week.
Add in backups: Our solutions let you store data with multiple providers or use AI to find unusual patterns. Test without mercy—use Chaos Monkey variants to make sure your dodges work.
Mastering Monitoring: Stay Ahead of the Game
Being proactive is better than being reactive: Combine Edge logs with Datadog to get alerts in real time, turning possible problems into wins before they happen. Discipline is what keeps your digital presence strong.
Conclusion: Get ahead of the game to keep growing
The AWS outage aftermath isn't a setback; it's a chance to show off smarter architectures like Next.js Edge, where distributed resilience turns threats into victories. Make your stack bulletproof today, and watch as downtime goes away and leads and sales go up.
Don't wait for the next storm. To see Edge in action, check out our portfolio. You can also get a free resilience audit by emailing [email protected]. At BYBOWU, we promise to keep you online and ahead. Let's build something that can't be broken together.


Comments
Be the first to comment.