
The November 18 Cloudflare outage was a blunt reminder that one proxy in the critical path can take your business down. For several hours, core traffic through Cloudflare’s network errored while related services like Workers KV, Access, and Turnstile saw knock-on failures. If a single vendor is between your users and your origin, you felt it. This piece offers a practical resilience plan grounded in real production tradeoffs.

What actually broke on November 18, 2025?
Cloudflare experienced a widespread incident beginning late morning UTC and worked through staged recovery in the afternoon. Core proxy traffic served elevated 5xx responses; dashboard logins failed when Turnstile couldn’t load; Workers KV front ends returned errors; Access authentication failed for new sessions. By late afternoon UTC, a rollback and configuration fix restored service. The point isn’t blame—it’s understanding system blast radius: when the proxy falls over, dependent products and any app logic coupled to them tend to fall with it.
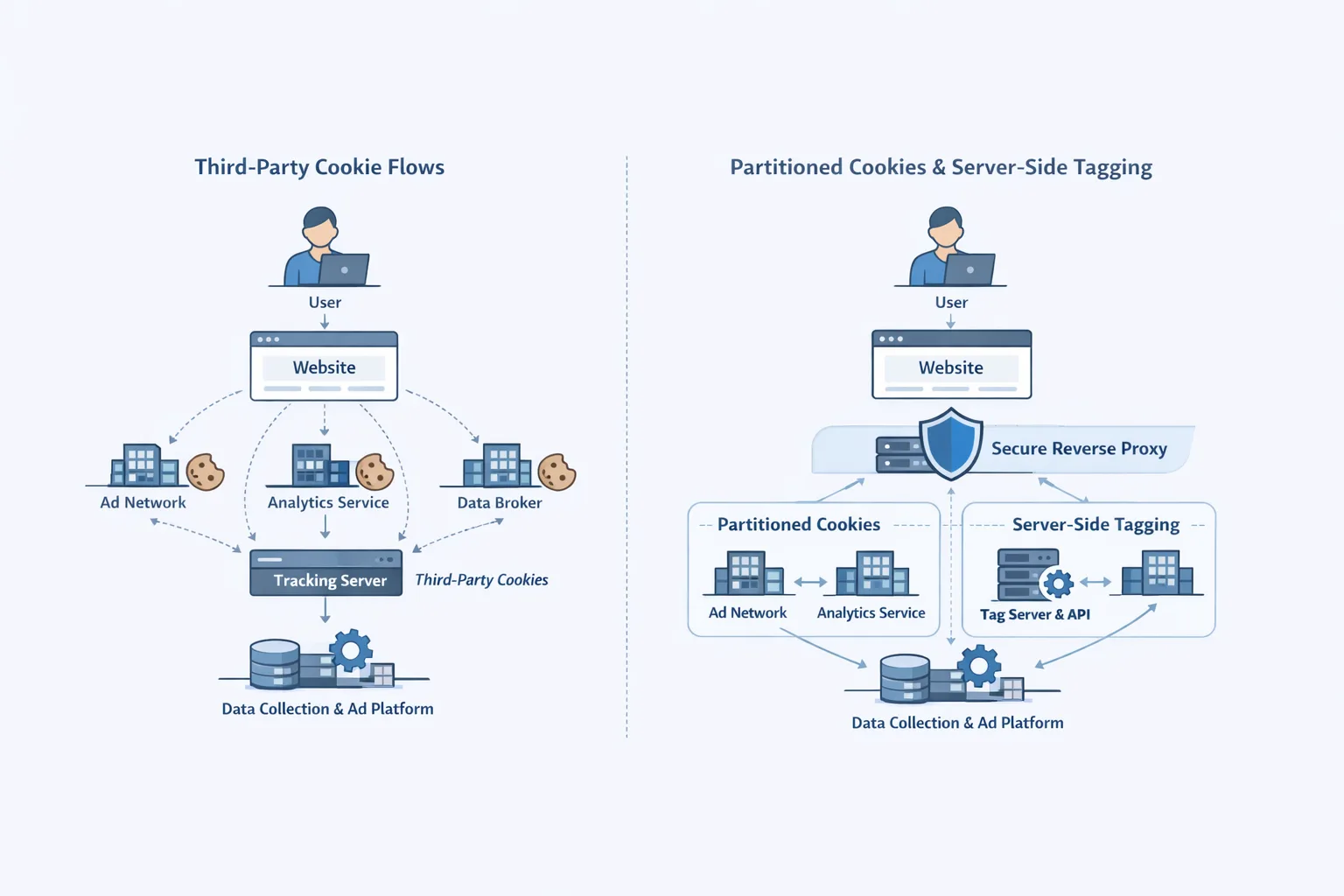
Why the recap? Because your architecture likely assumes the proxy is always available. Many teams route every request—public site, logged-in app, API, even internal admin tools—through the same edge and attach auth, bot management, and rate limiting there. That convenience centralizes risk. During the outage, applications that preserved an alternate path to the origin, or that could temporarily fail open for non-critical controls, stayed usable while everyone else disappeared.
The single-vendor trap (and how to step around it)
Here’s the thing: Cloudflare is excellent. That’s why so many of us use it for CDN, WAF, caching, image optimization, zero trust, and DNS. The issue isn’t Cloudflare per se; it’s monoculture. If your entire request lifecycle, from DNS to auth to bot detection, depends on one provider’s control plane and proxy, your mean time to recovery is limited by their incident timeline—not yours.
Resilience isn’t free. But there’s a pragmatic middle path: build a clean escape hatch to the origin, keep an alternate control plane ready, and practice switching—just like failover between database regions. Think of it as a “graceful degradation contract” your system signs with the business.
Primary keyword anchor: How to prepare for the next Cloudflare outage
Let’s get practical. Below is a step-by-step blueprint we use with teams that want real coverage without rebuilding their stack from scratch.
1) Put a clean origin bypass in place
Add an alternate hostname that resolves directly to your origin or to a second CDN, with TLS configured and access controls applied at the origin tier. Keep it private—only used by your apps and playbooks. The bypass lets you move critical flows off the impacted proxy while you maintain edge controls for everything else.
Key details to nail:
- Provision certs for the alternate hostname, rotated automatically.
- Gate with origin WAF rules scoped to that hostname and to known user agents or IP ranges you control.
- Make sure app cookies and CORS allow this hostname in a pinch.
2) Use dual DNS providers or a provider plus secondary
Even if DNS wasn’t the root cause, it’s your steering wheel in an incident. Maintain a warm backup DNS provider or a secondary zone you can promote. Keep TTLs low on switchover records, but not so low that resolvers ignore them—60–120 seconds is a practical baseline for public endpoints. Document exactly which records flip during a proxy-wide event, and test them quarterly.
3) Decide on multi-CDN with intent (not vibes)
Multi-CDN helps, but only if you control routing. A/B test with synthetic checks and real traffic mirrored to a second provider (Fastly, Akamai, CloudFront, etc.). Measure behavior on cache misses, header size limits, and TLS quirks. If a full multi-CDN is overkill, set up a “dark” secondary that can take over your most critical paths—login, checkout, and APIs—within 15 minutes.
4) Split control and data planes
Proxy outages often tangle with control planes. Keep operational toggles—feature flags, kill switches, env config—reachable even when the edge is unhappy. If your flags live behind the same proxy, you lose the very levers you need. Host runbooks, flags, and traffic-switch tools on infrastructure that doesn’t depend on the proxy in distress.
5) Make auth resilient to edge challenges
When Turnstile or a similar challenge system is unavailable, brand-new sessions can’t start. Build a temporary fallback for trusted scenarios: for example, allow a reduced challenge path for known customer networks, verified device tokens, or recently authenticated users. Preserve session extension for logged-in users so an outage doesn’t boot your workforce or paying customers. Log the exceptions and time-box the fallback with a kill switch.
6) Tune caching and TTLs for incident behavior
Many sites learned their HTML and API endpoints were essentially uncached during the outage. Cache what you can, even just for a few minutes, and embrace stale-while-revalidate and stale-if-error for non-personalized pages. For APIs, consider response-level caching keys that won’t leak user data: product listings, CMS fragments, and feature flags can often be cached per-tenant or per-role safely.
7) Have a plan for Workers KV and friends
If your app reads crucial config or content from Workers KV, model a secondary source of truth. Options include a read-through cache to your own store, a CDN-agnostic object store, or bundling critical config at deploy time with a rapid redeploy path. The rule: your most essential reads should not have a single, remote dependency you can’t override.
8) Don’t let observability sink the ship
During large failures, logging and tracing can become the heaviest workloads in your system. Implement per-tenant and per-route sampling you can dial down. Protect error queues so repeated retries and core dumps don’t exhaust CPU or memory on the hot path. It feels wrong to drop signals during a crisis—until you remember you’d rather serve users than drown in logs.
9) Practice the switch
Chaos engineering lite is enough. Once a quarter, simulate loss of your primary proxy in a staging environment that mirrors production DNS and CDNs. Rehearse the actual steps: change records, lower rate limits, flip WAF profiles, toggle bot protection fallback, and shift auth to a reduced challenge mode. Time the run, write down the sharp edges, and remove manual steps next sprint.

10) Negotiate vendor guardrails
SLAs won’t keep you online, but they can buy support attention and transparency. Ask for outage runbooks, emergency comms channels, and any feature flags you can control during their incident (e.g., disable a specific edge module). Make sure your account team knows you expect kill switches to be available and documented.
A simple blueprint you can copy
Let’s say you run a Next.js storefront with a global audience and a US‑East origin. Here’s a minimal, high-leverage setup that survives a Cloudflare-wide issue:
Public traffic uses Cloudflare for CDN, WAF, and bot mitigation. In parallel, you provision a secondary CDN for only three paths: /api/*, /login, and /checkout. You keep an alternate hostname—say, internal.example.net—fronted by that secondary. Certificates are in place and renewed. The origin WAF allows internal.example.net traffic with stricter IP rate limits. Your app supports this host in CORS and cookies (SameSite and domain attributes verified). DNS contains pre-staged records for internal.example.net with 60-second TTLs, managed by a secondary provider so you can switch even if your primary control plane stalls.
You configure cache rules so the homepage, category pages, and CMS fragments have short TTLs with stale-if-error. Your login page renders a Turnstile widget when it’s healthy, but the code can fall back to an email magic link for verified devices when the challenge provider is down, gated by that alternate hostname and a temporary velocity cap. Feature flags and the status page live outside the impacted proxy and remain accessible. Once a quarter, you practice: you cut the primary CDN from the three critical paths, flip DNS to the alternate hostname, and re-run smoke tests. It takes eight minutes. Users notice a small slowdown; revenue stays intact.
People also ask
Can multi‑CDN prevent every outage?
No. It reduces the probability of a front‑door failure, but you must still decouple state and auth from a single control plane. Multi‑CDN without origin hardening and auth fallbacks is false comfort.
Should we disable bot challenges or Turnstile during incidents?
Don’t globally disable them. Instead, build a narrow, temporary bypass: specific endpoints, known tenants, or device tokens with short expirations. Combine with stricter rate limits and extra logging so you can unwind later.
What’s a safe DNS TTL in practice?
For records you might flip in an emergency, 60–120 seconds is a good balance. For everything else, longer TTLs are healthier for resolvers and performance. Test resolver behavior; some recursive resolvers cap how low they’ll honor.
Is a static emergency page worth it?
Yes—if it’s truly static and hosted off the impacted path. Point marketing pages or critical help content to a static host that’s reachable even when your primary proxy is unhealthy. Keep it current and link to your status page.
The resilience checklist (printable)
Use this when you don’t have time to debate architecture during an incident. If you can’t check an item, add it to the next sprint.
- Alternate hostname to origin or secondary CDN is live, with TLS and origin WAF scoped to it.
- Secondary DNS provider or warm zone exists; change window and records are documented.
- Critical flows identified: login, checkout, API. Each has tested cache or fallback behavior.
- Auth fallback designed: reduced challenge path for trusted contexts; temporary velocity caps.
- Workers KV or similar state has a secondary read path or bundled config for critical reads.
- Feature flags, runbooks, and status live outside the primary proxy.
- Observability sampling can be throttled; queues won’t take down the hot path.
- Quarterly failover rehearsal scheduled with success criteria and timings captured.
- Vendor account notes contain incident playbooks and escalation channels.
Zooming out: you’re building an incident muscle
If the outage forced hard conversations, use the momentum. The work isn’t a rewrite; it’s targeted scaffolding around the sharp edges of your dependency on a single proxy. When pricing or product boundaries shift—think of the recent Cloudflare Containers pricing changes—teams feel the same fragility. The antidote is the same: minimize blast radius, keep an exit path warm, and practice flipping it.
We’ve helped teams weather platform changes, like npm token changes that broke CI/CD. Different vendor, same principle: assume the control plane will bite you at 3 a.m., and make the switch boring. If you want help stress-testing your setup or building the “boring switch,” see what we do or just talk to us.
What to do this week
If you only have a few hours, here’s the 80/20:
- Provision an alternate hostname, certs, and origin WAF profile. Validate cookies and CORS.
- Stand up a secondary DNS zone or provider and document the exact flip steps.
- Cache the obvious: homepage, category pages, CMS fragments, and any safe API responses with stale-if-error.
- Ship an auth fallback for new sessions—tight scope, short TTL, kill switch included.
- Stage a secondary for three endpoints: /login, /checkout, /api. Rehearse a cutover.
You don’t have to abandon Cloudflare to be resilient to a future Cloudflare outage. You just need to own your failure modes. Build the escape hatches now, label the switches, and practice enough that you can flip them while half the team is still on the incident bridge. That’s operational maturity—and it pays for itself the first time you dodge a headline.



Comments
Be the first to comment.