
On November 18, a widespread Cloudflare outage produced waves of 5xx errors and intermittent failures across login flows, dashboards, and APIs that rely on Cloudflare’s edge. Large brands and fast‑growing apps felt it. If your incident channel lit up with “Is it us or them?”, you’re not alone—and you shouldn’t wait for the next domino to fall.
Here’s the thing: outages at the edge don’t just slow you down—they can sever revenue at the exact moment you need reliability most. The good news is you can ship meaningful defenses quickly. Below is a clear, opinionated plan to reduce blast radius, keep cash registers ringing, and stop single points of failure from taking your business offline.

What actually failed on Nov 18?
The incident involved a configuration file used by a bot detection module. A database permissions change caused duplicate rows, doubling the file size. That larger file propagated across the network and tripped a size limit in proxy software, producing 5xx errors. Some services flipped between “working” and “failing” as different nodes generated good vs. bad files until the rollout was halted and a known‑good version redeployed. Core traffic improved after the rollback, and the long tail of recovery cleared as downstream systems restarted and backlogs drained.
Key surface areas that saw disruption included:
- Core CDN and security traffic returning 5xx errors.
- Turnstile not loading, which broke logins and any page that required a challenge.
- Workers KV erroring due to upstream proxy failures, with downstream systems impacted.
- Access authentication errors for new sessions; existing sessions largely unaffected.
Translation for product teams: if your app depended on scripts or APIs hosted behind the affected edge path—especially authentication or risk checks—users were locked out, carts stalled, and dashboards timed out.
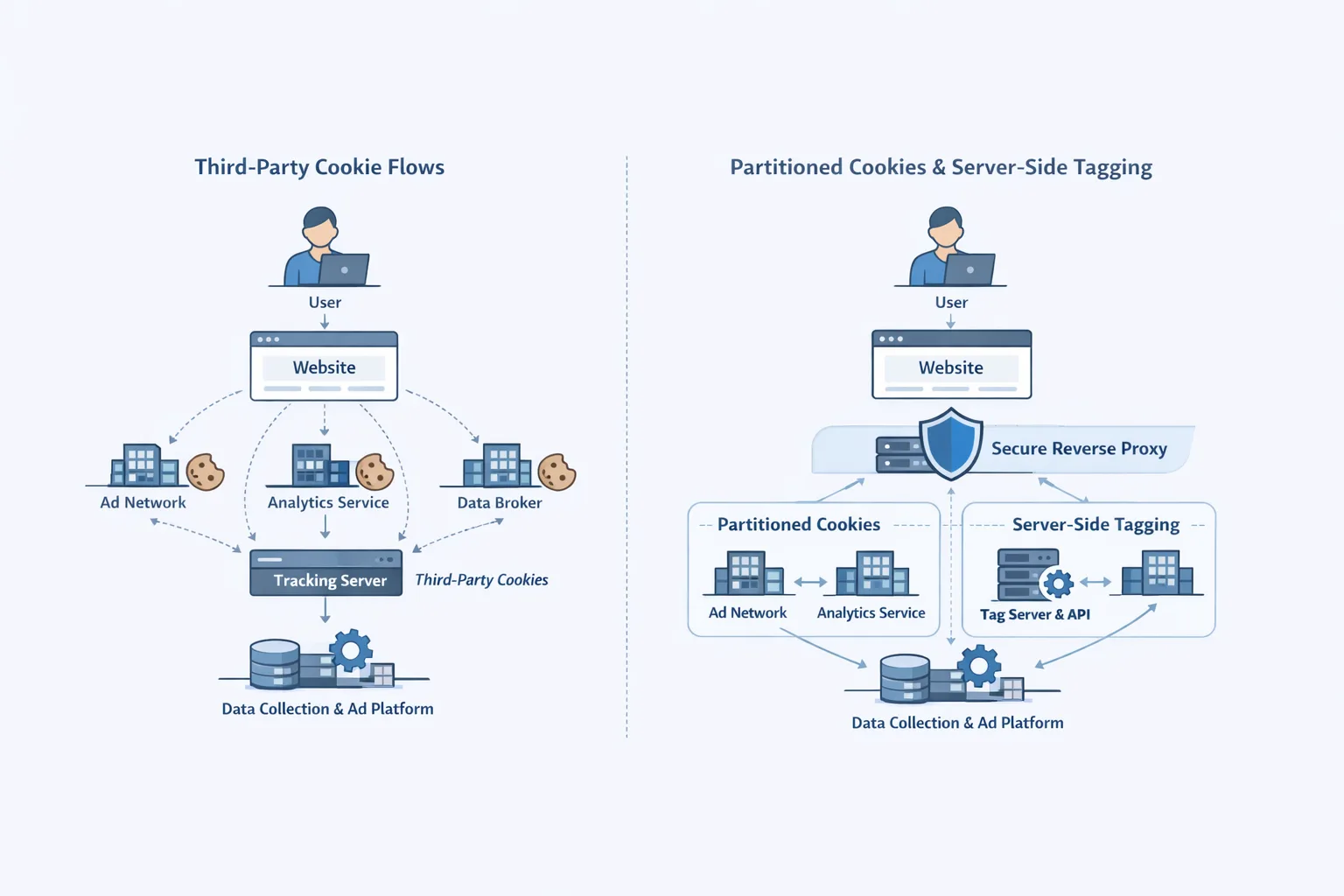
Why one vendor can take you down
Modern stacks centralize at the edge for good reasons: speed, security, and developer velocity. But entangling essential user journeys—login, pay, create—behind a single vendor’s JavaScript, proxy, or KV means their bad day becomes your lost revenue. The dependency isn’t just your CDN; it’s the modules you allow into your critical path: bot scoring, WAF decisions, turnstile challenges, and edge storage powering feature flags or configuration.
Zooming out, three patterns amplify risk:
- Single‑path control planes embedded in runtime flows (e.g., login pages blocked by a third‑party challenge failing to load).
- Stateful edge dependencies with brittle fallbacks (e.g., KV lookups required to render a page at all).
- All‑or‑nothing auth and risk checks (e.g., “no score = no service”, instead of “no score = low‑risk allow with extra logging”).
Cloudflare outage lessons for architects
Let’s get practical. If the November 18 Cloudflare outage caused pain, adopt these twelve steps. You don’t need unlimited budget. You need deliberate design and a bias to ship safeguards in the next sprint.
1) Build a multi‑CDN front door (but do it sanely)
Start with DNS‑level health‑aware routing (e.g., weighted or failover records) between two providers. Keep 80–90% traffic on your primary, 10–20% on a secondary to avoid cold‑start surprises. Pro tip: standardize TLS certs and headers across both edges now; mismatches are what bite you at 2 a.m.
2) Fail open for auth challenges
If a turnstile or captcha script fails to load within a tight SLA (say 800 ms on broadband), bypass the challenge and log the event with a “low confidence” flag for post‑hoc analysis. Pair with anomaly detection and rate limits to cap abuse. “No widget, no login” should not be a thing.
3) Make bot scores advisory, not absolute
When a risk score is missing or stale, default to the least‑privileged success path, not failure. For example, allow browsing and add friction only at irreversible steps (checkout confirm, wire transfer submit). Cache the last good score in a short‑lived, signed cookie to smooth blips.
4) Serve-stale-on-error across the stack
Adopt stale‑while‑revalidate and stale‑if‑error aggressively for product pages, articles, and dashboards that can tolerate slightly old data. It’s better to show a cached profile or cart and queue updates than to throw a 5xx. If you’re on Next.js, review our Next.js 16 caching and proxy guide for practical patterns.
5) Keep your login and pay pages “edge‑light”
Critical flows should render without any third‑party script completing. Inline the minimum CSS, precompute layouts, and isolate external widgets behind quick timeouts with graceful degradation. If the risk engine is down, capture the order, mark it for review, and notify the ops channel.
6) Give your app an offline brain
A defensive service worker can deliver a “connectivity degraded” shell with recent cache for navigation, while queueing writes for later. This is especially effective for dashboards and CRMs. Don’t aim for perfection—give users a way to keep moving.
7) De‑entangle your control plane from runtime
Feature flags, config, and experiments shouldn’t block rendering. Pull them from two sources (edge + origin or replicated store) with a safe default baked into the bundle. If KV or a remote config fails, fall back to the last known snapshot shipped with the release.
8) Instrument “over the edge” health
Synthetic checks must test real user paths both through and around your CDN. Measure “origin direct” health and maintain a secret, DNS‑bypassed path for last‑ditch failover. Alert on rising “challenge not loaded” and “missing risk score” rates, not just 5xx.
9) Keep a manual kill switch for risky modules
Be able to disable bot scoring, challenge injection, or experimental middleware globally from a separate control channel. Test this monthly. If the outage was fueled by a config file, your defense is the ability to ignore it.
10) Reduce cross‑blast between products
Segment edge modules by function: static, dynamic, APIs. If bot management fails in one plane, it shouldn’t cascade to KV or login. Use distinct subdomains and tailored rulesets, not “one profile to rule them all.”
11) Choose “good enough” consistency for user perception
Favor UX continuity over strict freshness during incidents. Show the last known account balance with a “Updated a few minutes ago” label and retries. Users accept slight staleness; they don’t accept “Service Unavailable.”
12) Rehearse the flip
Tabletop it. Can you move 50% of traffic to the secondary CDN in five minutes? Can you bypass a broken challenge across all regions from a phone? Practice makes your chaos day boring.

Data you can act on
There are two practical thresholds that convert theory into engineering:
- Timeout budgets: set 300–800 ms for third‑party modules in the critical path before you degrade gracefully. This keeps TTFB and INP reasonable during stress.
- Staleness windows: pick per‑page expirations. Product/detail: 5–15 minutes. Marketing/blog: hours. Pricing: seconds to minutes, with server‑side revalidation.
If you’re measuring Core Web Vitals, you already know that faster perceived response reduces both bounce and fraud pressure. A resilience‑first cache strategy helps you pass INP and maintain profitable sessions when the network is shaky.
Mini‑framework: The “3x2” Resilience Matrix
Use this to decide what gets fail‑open, stale‑serve, or hard‑fail.
Three journeys: browse, login, pay. Two modes: normal, degraded.
- Browse: always serve stale on error; block only on known bad signals. Prefetch hero images and price snippets.
- Login: fail open if challenge is unreachable; require step‑up only upon risk signals (IP mismatch, device novelty, velocity).
- Pay: never fail open on irreversible transfers; do queue‑and‑confirm. Show “We’ll email confirmation” and reconcile asynchronously.
Write this down in your runbook so engineers don’t debate it under sirens.
People also ask
Do I really need multi‑CDN, or is that overkill?
If your revenue, SLAs, or brand depend on uptime, yes—though “multi‑CDN” can be pragmatic. Start with DNS failover and a small steady trickle to a secondary provider. Keep headers, TLS, and cache semantics aligned so you can flip without a multi‑week drama.
Will stale‑while‑revalidate actually help during a Cloudflare outage?
It does when combined with serve‑stale‑on‑error and prewarming. Your goal is to render something fast, then retry in the background. Pair with a service worker to hold the shell and queue writes. We detail cache nuances—and how proxies behave under stress—in our Next.js 16 deep dive.
How do I protect logins if Turnstile or a risk script fails?
Guard with timeouts and explicit fallbacks. If a script doesn’t load within budget, render the form, rate‑limit submissions, and require a step‑up only on risky patterns. Cache the prior successful risk state briefly so benign users aren’t repeatedly challenged.
Won’t bot abuse spike if I fail open?
If you fail open without controls, yes. But you can cap risk with IP/ASN velocity checks, device reputation, and optimistic operations that are easily reversible. The key is “low‑risk success” versus “no service at all.”
30‑day upgrade path you can actually ship
Here’s a sequence we’ve used with product teams to cut outage pain fast:
- Week 1: instrument “challenge not loaded”, “missing score”, and “KV read failed” counters; wire alerts. Add serve‑stale‑on‑error headers for all cacheable pages.
- Week 2: impose strict timeouts on third‑party scripts in checkout and login; implement fail‑open paths; inline critical CSS; prefetch auth endpoints.
- Week 3: deploy DNS‑level failover with a secondary CDN, route 10% traffic; standardize certs and headers; validate cache keys and purge flows.
- Week 4: add a service worker with a navigation fallback; snapshot feature flags into the bundle; create a one‑click kill switch for edge modules.
If you’re modernizing your app simultaneously, our Next.js 16 Migration: The 30‑Day Playbook shows how to add caching layers and streaming without breaking production. Need help planning the rollout? See what we do for architecture and SRE sprints or reach out via our contact page.
Operational guardrails to stop the next cascade
Technology changes fast; guardrails are your constant. Put these on autopilot:
- Change windows with auto‑rollback: if error budgets or specific counters spike for 5 minutes post‑change, revert.
- Cross‑plane isolation: keep bot, WAF, KV, and login flows from sharing identical failure modes. Separate subdomains and rulesets.
- Warm backups: every Friday, send 5–10% traffic through your backup CDN and origin path. Measure and fix the drift.
- Chaos drills: break the challenge script, simulate KV timeouts, and practice DNS flips. Reward teams for boring outcomes.
The business angle: quantify the upside
Resilience work often wins the argument when you can model avoided losses. Back‑of‑napkin is fine. If your peak conversion rate is 3% and 40,000 sessions hit during a two‑hour window, a 5xx storm that blocks 60% of checkouts can burn high five figures to six figures depending on AOV. Two such incidents a year often justify a secondary CDN, engineering time for fallbacks, and observability upgrades.
What to do next
- Map every third‑party dependency on your login, pay, and create paths. Decide fail‑open vs. block and document it.
- Ship stale‑while‑revalidate plus stale‑if‑error for cacheable routes; prewarm top 100 pages hourly.
- Put a 10% shadow route through your secondary CDN and monitor for header/cert drift.
- Add an “origin direct” path you can toggle if your edge melts.
- Run a one‑hour drill: cut the challenge script and KV; validate users can still log in and view account data.
Incidents like the November 18 Cloudflare outage will happen again—somewhere, to someone. Your job isn’t to predict the next vendor to falter; it’s to design your product so customers barely notice when one does. If you want a partner who has done the migrations, tuned the caches, and rehearsed the flips, talk to us. We build resilient, fast experiences that keep you online when it matters most. Explore our services and recent work, then ping us via Contacts. We’re ready when you are.



Comments
Be the first to comment.